Кросс-валидация
Кросс-валидация или скользящий контроль — процедура эмпирического оценивания обобщающей способности алгоритмов. С помощью кросс-валидации эмулируется наличие тестовой выборки, которая не участвует в обучении, но для которой известны правильные ответы.
Содержание
Определения и обозначения [ править ]
Пусть [math] X [/math] — множество признаков, описывающих объекты, а [math] Y [/math] — конечное множество меток.
[math]T^l = <(x_i, y_i)>_
[math]Q[/math] — мера качества,
[math]\mu: (X \times Y)^l \to A, [/math] — алгоритм обучения.
Разновидности кросс-валидации [ править ]
Валидация на отложенных данных (Hold-Out Validation) [ править ]
Обучающая выборка один раз случайным образом разбивается на две части [math] T^l = T^t \cup T^

После чего решается задача оптимизации:
Метод Hold-out применяется в случаях больших датасетов, т.к. требует меньше вычислительных мощностей по сравнению с другими методами кросс-валидации. Недостатком метода является то, что оценка существенно зависит от разбиения, тогда как желательно, чтобы она характеризовала только алгоритм обучения.
Полная кросс-валидация (Complete cross-validation) [ править ]

Здесь число разбиений [math]C_l^
k-fold кросс-валидация [ править ]
Каждая из [math]k[/math] частей единожды используется для тестирования. Как правило, [math]k = 10[/math] (5 в случае малого размера выборки).
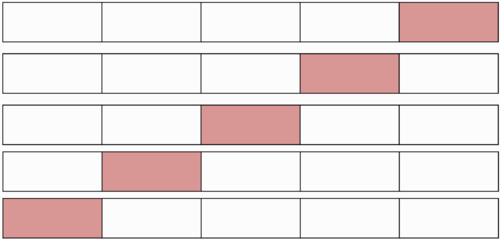
t×k-fold кросс-валидация [ править ]
Кросс-валидация по отдельным объектам (Leave-One-Out) [ править ]
Выборка разбивается на [math]l-1[/math] и 1 объект [math]l[/math] раз.
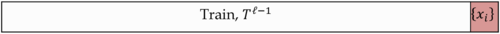
Преимущества LOO в том, что каждый объект ровно один раз участвует в контроле, а длина обучающих подвыборок лишь на единицу меньше длины полной выборки.
Недостатком LOO является большая ресурсоёмкость, так как обучаться приходится [math]L[/math] раз. Некоторые методы обучения позволяют достаточно быстро перенастраивать внутренние параметры алгоритма при замене одного обучающего объекта другим. В этих случаях вычисление LOO удаётся заметно ускорить.
Случайные разбиения (Random subsampling) [ править ]
Выборка разбивается в случайной пропорции. Процедура повторяется несколько раз.
Критерий целостности модели (Model consistency criterion) [ править ]
Не переобученый алгоритм должен показывать одинаковую эффективность на каждой части.

Об обучении, валидации и тестовых наборах в машинном обучении
Дата публикации Dec 6, 2017

Это делается для того, чтобы стать кратким учебником для всех, кому необходимо знать разницу между различными разбиениями набора данных при обучении моделям машинного обучения.
Для этой статьи я бы процитировал базовые определения изОтличная статья Джейсона Браунлина ту же тему, это довольно всеобъемлющий, если вам нравится больше деталей, проверьте это.
Учебный набор данных
Учебный набор данных: Образец данных, используемых для соответствия модели.
Фактический набор данных, который мы используем для обучения модели (веса и смещения в случае нейронной сети). Модельвидита такжеузнаетиз этих данных.
Набор данных проверки
Набор данных проверки: Выборка данных, используемая для объективной оценки соответствия модели учебному набору данных при настройке гиперпараметров модели. Оценка становится более предвзятой, поскольку навык набора данных проверки включается в конфигурацию модели.
Набор проверки используется для оценки данной модели, но это для частой оценки. Мы, как инженеры машинного обучения, используем эти данные для точной настройки гиперпараметров модели. Отсюда и модель изредкавидитэти данные, но никогда не делает этоУчиться» из этого. Мы (в основном люди, по крайней мере, по состоянию на 2017 г.) используем результаты проверочного набора и обновляем гиперпараметры более высокого уровня. Таким образом, набор проверок влияет на модель, но косвенно.
Тестовый набор данных
Тестовый набор данных: Выборка данных, используемых для объективной оценки окончательной модели, подходящей для набора данных обучения.
Набор данных Test предоставляет золотой стандарт, используемый для оценки модели. Он используется только после того, как модель полностью обучена (с использованием наборов поездов и валидации). Набор тестов, как правило, используется для оценки конкурирующих моделей (например, на многих соревнованиях Kaggle набор валидации выпускается изначально вместе с тренировочным набором, а фактический набор тестов выпускается только тогда, когда соревнование подходит к концу, и это результат модели на тестовом наборе, который определяет победителя). Много раз набор проверки используется как набор тестов, но это не очень хорошая практика. Тестовый набор, как правило, хорошо курируется. Он содержит тщательно отобранные данные, охватывающие различные классы, с которыми столкнется модель при использовании в реальном мире.

О коэффициенте разделения набора данных
Теперь, когда вы знаете, что делают эти наборы данных, вы можете искать рекомендации о том, как разделить ваш набор данных на наборы Train, Validation и Test…
Это в основном зависит от 2 вещей. Во-первых, общее количество образцов в ваших данных, а во-вторых, на реальной модели, которую вы тренируете.
Некоторые модели нуждаются в существенных данных для обучения, поэтому в этом случае вы бы оптимизировали для больших тренировочных наборов. Модели с очень небольшим количеством гиперпараметров будет легко проверить и настроить, так что вы, вероятно, сможете уменьшить размер своего набора проверки, но если в вашей модели много гиперпараметров, вы также захотите иметь большой набор проверки (хотя вы также должны учитывать перекрестная проверка). Кроме того, если у вас есть модель без гиперпараметров или модели, которые не могут быть легко настроены, вам, вероятно, не понадобится и набор проверки!
В целом, как и многие другие вещи в машинном обучении, коэффициент разделения обучения и проверки достоверности также весьма специфичен для вашего варианта использования, и вам становится легче оценивать, когда вы обучаете и строите все больше и больше моделей.
Дайте мне знать в комментариях, если вы хотите обсудить что-либо из этого дальше. Я также учусь, как и многие из вас, но я обязательно постараюсь помочь всем, чем смогу.
Validating your Machine Learning Model
Going beyond k-Fold Cross-Validation

Sep 26, 2019 · 8 min read
I believe that one of the most underrated aspects of creating your Machine Learning Model is thorough validation. Using proper validation techniques helps you understand your model, but most importantly, estimate an unbiased generalization performance.
There is no single validation method that works in all scenarios. It is important to understand if you are dealing with groups, time-indexed data, or if you are leaking data in your validation procedure.
Which validation method is right for my use case?
When researching these aspects I found plenty of articles describing evaluation techniques, but validation techniques typically stop at k-Fold cross-validation.
I would lik e to show you the world that uses k-Fold CV and goes one step further into Nested CV, LOOCV, but also into model selection techniques.
The following methods for validation will be demonstrated:
1. Splitting your data
The basis of all validation techniques is splitting your data when training your model. The reason for doing so is to understand what would happen if your model is faced with data it has not seen before.
Train/test split
The most basic method is the train/test split. The principle is simple, you simply split your data randomly into roughly 70% used for training the model and 30% for testing the model.
The benefit of this approach is that we can see how the model reacts to previously unseen data.
However, what if one subset of our data only have people of a certain age or income levels? This is typically referred to as a sampling bias:
Sampling bias is systematic error due to a non-random sample of a population, causing some members of the population to be less likely to be included than others, resulting in a biased sample.

Before going into methods that help with the sampling bias (like k-Fold cross-validation), I would like to go into the additional holdout set.
Holdout set
When optimizing the hyperparameters of your model, you might overfit your model if you were to optimize using the train/test split.
Why? Because the model searches for the hyperparameters that fit the specific train/test you made.
To solve this issue, you can create an additional holdout set. This is often 10% of the data which you have not used in any of your processing/validation steps.

After optimizing your model on the train/test split, you can check if you did not overfit by validating on your holdout set.
TIP: If only use a train/test split, then I would advise comparing the distributions of your train and test sets. If they differ significantly, then you might run into problems with generalization. Use Facets to easily compare their distributions.
2. k-Fold Cross-Validation (k-Fold CV)
To minimize sampling bias we can think about approach validation slightly different. What if, instead of making a single split, we make many splits and validate on all combinations of those splits?
This is where k-fold cross-validation comes in. It splits the data into k folds, then trains the data on k-1 folds and test on the one fold that was left out. It does this for all combinations and averages the result on each instance.

The advantage is that all observations are used for both training and validation, and each observation is used once for validation. We typically choose either i=5 or k=10 as they find a nice balance between computational complexity and validation accuracy:
TIP: The scores of each fold from cross-validation techniques are more insightful than one may think. They are mostly used to simply extract the average performance. However, one might also look at the variance or standard deviation of the resulting folds as it will give information about the stability of the model across different data inputs.
3. Leave-one-out Cross-Validation (LOOCV)
A variant of k-Fold CV is Leave-one-out Cross-Validation (LOOCV). LOOCV uses each sample in the data as a separate test set while all remaining samples form the training set. This variant is identical to k-fold CV when k = n (number of observations).

It can be easily implemented using sklearn:
NOTE: LOOCV is computationally very costly as the model needs to be trained n times. Only do this if the data is small or if you can handle that many computations.
Leave-one-group-out Cross-Validation (LOGOCV)
The issue with k-Fold CV is that you might want each fold to only contain a single group. For example, let’s say you have a dataset of 20 companies and their clients and you want to predict the success of these companies.

To keep the folds “pure” and only contain a single company you would create a fold for each company. That way, you create a version of k-Fold CV and LOOCV where you leave one company/group out.
Again, implementation can be done using sklearn:
4. Nested Cross-Validation
When you are optimizing the hyperparameters of your model and you use the same k-Fold CV strategy to tune the model and evaluate performance you run the risk of overfitting. You do not want to estimate the accuracy of your model on the same split that you found the best hyperparameters for.
Instead, we use a Nested Cross-Validation strategy allowing to separate the hyperparameter tuning step from the error estimation step. To do this, we nest two k-fold cross-validation loops:

The example below shows an implementation using k-Fold CV for both the inner and outer loop.
You are free to select the cross-validation approaches you use in the inner and outer loops. For example, you can use Leave-one-group-out for both the inner and outer loops if you want to split by specific groups.
5. Time Series CV
Now, what would happen if you were to use k-Fold CV on time series data? Overfitting would be a major concern since your training data could contain information from the future. It is important that all your training data happens before your test data.
One way of validating time series data is by using k-fold CV and making sure that in each fold the training data takes place before the test data.

Fortunately, sklearn is again to the rescue and has a Time Series CV builtin:
NOTE: Make sure to order your data according to the time index that you use seeing as you do not supply the TimeSeriesSplit with a time index. Thus, it will create the split simply based on the order in which the records appear.
6. Comparing Models
When do you consider one model to be better than another? If one model’s accuracy is insignificantly higher than another, is that a sufficient enough reason for choosing the best model?
As a Data Scientist, I want to make sure that I understand if a model is actually significantly more accurate than another. Fortunately, many methods exist that apply statistics to the selection of Machine Learning models.
Wilcoxon signed-rank test
One such method is the Wilcoxon signed-rank test which is the non-parametric version of the paired Student’s t-test. It can be used when the sample size is small and the data does not follow a normal distribution.
We can apply this significance test for comparing two Machine Learning models. Using k-fold cross-validation we can create, for each model, k accuracy scores. This will result in two samples, one for each model.
Then, we can use the Wilcoxon signed-rank test to test if the two samples differ significantly from each other. If they do, then one is more accurate than the other.
Валидация моделей машинного обучения

На связи команда Advanced Analytics GlowByte и сегодня мы разберем валидацию моделей.
Иногда термин «валидация» ассоциируется с вычислением одной точечной статистической метрики (например, ROC AUC) на отложенной выборке данных. Однако такой подход может привести к ряду ошибок.
В статье разберем, о каких ошибках идет речь, подробнее рассмотрим процесс валидации и дадим ответы на вопросы:
Расширяем понятие валидации
Что не так с валидацией как вычислением одной точечной статистической метрики на отложенной выборке данных?
Аргумент против № 1: одна метрика не может учесть все аспекты качества модели. Качество модели измеряется не только предсказательной способностью, но и, например, стабильностью во времени.
Аргумент против № 2: количественные оценки не всегда согласуются с бизнес-метриками и поэтому вводятся дополнительные. Например, мы можем разработать модель с хорошей интегральной оценкой, но при попытке интерпретации модели в разрезе отдельных факторов может выясниться, что фактор, который по бизнес-логике при увеличении значения должен снижать прогнозный показатель, в разработанной модели, наоборот, его повышает.
Аргумент против № 3: точечная оценка может варьировать в зависимости от состава валидационной выборки, особенно это касается не сбалансированных выборок (с соотношением классов 1:50 или более значимым перекосом). Поэтому стоит дополнительно делать интервальные оценки.

Аргумент против № 4: актуальные данные могут отличаться от исторических, на которых была построена модель, поэтому валидацию стоит делать и на актуальном срезе данных.
Аргумент против № 5: реальные проекты обычно представляют собой набор неоднородных (по сложности и перечню используемых технологий) скриптов, в которых могут быть неточности или неучтенные варианты поведения. Поэтому для корректной работы всего проекта необходимо проводить дополнительную проверку реализации модели, подготавливаемой к развертыванию, причем стоит учитывать не только зависимости между скриптами в проекте, но и порядок их запуска: при несоблюдении порядка они могут отработать без ошибок, но сформировать абсолютно не верный результат.
Валидация и жизненный цикл модели
Валидация — комплексный процесс, который осуществляется на протяжении всего жизненного цикла модели. Ее можно декомпозировать на составные части в соответствии с этапами жизненного цикла. На схеме ниже обозначено:

Профилирование (аудит витрины) осуществляется на этапе подготовки данных. Здесь проверяется соответствие собранных данных поставленной задаче, а также с помощью простых метрик (например, число пропусков в данных, диапазон значений в разрезе отдельных атрибутов) определяется качество витрины.
Когда модель построена, выполняется первичная валидация, чтобы доказать работоспособность и оценить целесообразность внедрения разработанной модели.
На этапе внедрения проводится два вида проверок.
Тут может появиться вопрос, чем валидация отличается от мониторинга. Если коротко, то мониторинг — более легковесный процесс, проводимый с большей частотой.

Методика валидации
Все используемые при валидации тесты можно разделить на две группы: количественные и качественные.
В качестве артефакта по результатам валидации предоставляется отчет:
Рассмотрим детальнее список тестов для моделей бинарной классификации на примере модели прогноза вероятности дефолта (PD-модели) по кредитному договору (подробнее о PD-моделях см. [1]).

Количественная оценка
К группе относятся расчеты метрик и статистические тесты, которые оценивают качество модели на разных этапах и разных уровнях (перечисляем не все, возможны и другие).
1. Дискриминационная способность модели
После разработки модели первый вопрос, который интересует бизнес-заказчика: а насколько хорошо модель справляется со своей задачей? Если мы построили PD-модель, то этот вопрос звучит так: насколько хорошо модель отделяет клиентов, которые уйдут в дефолт, от тех, кто в дефолт не уйдет, и насколько лучше эта модель, чем случайное угадывание?
Чтобы ответить на это вопрос, проводим тесты:
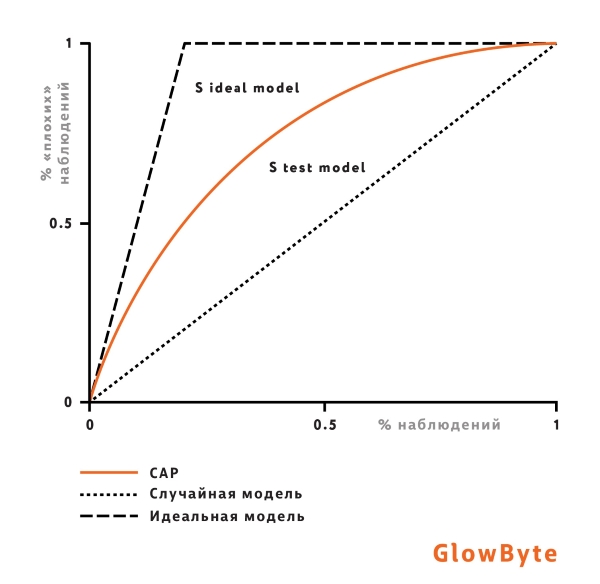
В случае бинарного целевого события коэффициент Джини рассчитывается как отношение площадей двух фигур:

Альтернативный способ определения метрики — пузырьковая сортировка (подробнее см. [2]). Пусть имеется список значений целевого события, порядок в котором совпадает с порядком значений вероятности, прогнозируемых моделью. Тогда показатель Swaps будет обозначать количество перестановок соседних элементов для приведения списка целевых событий к отсортированному виду без инверсий.
На примере ниже число таких перестановок Swaps = 2.
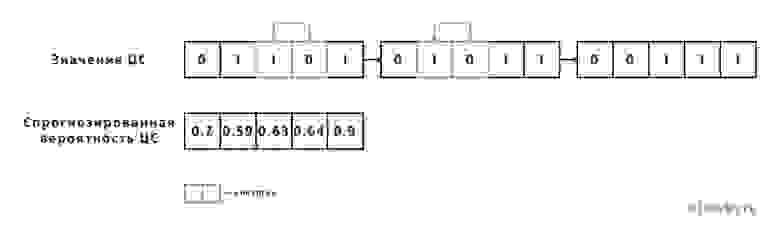
где:  – число перестановок для валидируемой модели,
– число перестановок для валидируемой модели,  – для случайной модели.
– для случайной модели.
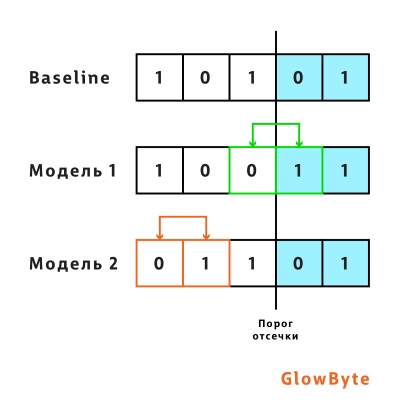
Однако, как видно из такой интерпретации, рост коэффициента Джини не всегда означает повышение пользы модели для бизнеса, поскольку не подразумевает изменения в ранжировании в сегменте пользователей, который интересен с точки зрения бизнеса. Ведь при подсчете перестановок не учитываются позиции элементов: на рисунке ниже отображены две возможные модели, которые улучшают базовую на одну перестановку: до порога отсечки и после. Обе модели одинаково улучшат значение метрики Джини, но с точки зрения бизнес-постановки задачи первая модель лучше, так как улучшает ранжирование после порога, среди клиентов, которым будет выдан кредит. Поэтому наравне с Джини нужны другие метрики — о них дальше.
О расчете коэффициента Джини для небинарных целевых событий см. в статье из цикла про риск-моделирование ([3]).
Если выборки не сбалансированы, то используется интервальная оценка с помощью техники бутстрэп. На основе исходной выборки генерируется B (
1000 и более) подвыборок, для каждой из которых рассчитывается коэффициент Джини. Затем проверяется, что заданный заранее перцентиль полученного распределения не пересекает фиксированный порог (например, если 2.5% перцентиль распределения коэффициентов Джини меньше 30%, то по тесту может быть выставлена оценка в виде красного сигнала).
Однако формирование подвыборок с помощью бутстрэпа – вычислительно сложная задача, которая может занять длительное время. С целью ее ускорения используется пуассоновский бутстрэп.
Извлечение с повторением элементов выборки размера n с фиксированной вероятностью  можно заменить на сэмплирование с помощью биномиального распределения
можно заменить на сэмплирование с помощью биномиального распределения  частот появления каждого элемента выборки. При условии достаточно большого размера выборки выполняется следующий переход от биномиального распределения к пуассоновскому [4]:
частот появления каждого элемента выборки. При условии достаточно большого размера выборки выполняется следующий переход от биномиального распределения к пуассоновскому [4]:
2. Оценка стабильности
Мы разработали модель, проверили ее дискриминационную способность, задеплоили, но спустя несколько месяцев показатели нашей модели ухудшились. После выяснения причин оказалось, что для обучения были отобраны нерепрезентативные данные. Вернемся назад во времени, попробуем предотвратить такую ситуацию и добавим еще один блок в отчет о валидации: стабильность.
где:  — доля наблюдений с i-м значением фактора;
— доля наблюдений с i-м значением фактора;  — количество наблюдений, соответствующих i-му значению фактора;
— количество наблюдений, соответствующих i-му значению фактора;  — общее количество наблюдений в выборке (
— общее количество наблюдений в выборке (  — валидационная выборка,
— валидационная выборка,  — выборка для разработки). (Если вы хотите почитать, в каких случаях еще используется PSI, см. например, статью про моделирование компоненты LGD из цикла про риск-моделирование [3].)
— выборка для разработки). (Если вы хотите почитать, в каких случаях еще используется PSI, см. например, статью про моделирование компоненты LGD из цикла про риск-моделирование [3].)
Один из способов интерпретации PSI – через дивергенцию Кульбака–Лейблера [5], меру удаленности двух распределений P и Q:
Мера несимметрична ( ) и из двух срезов данных мы не можем выбрать априорное распределение, с которым будет проводиться сравнение, поэтому для симметричности оценки можно использовать сумму двух мер от P до Q и от Q до P:
) и из двух срезов данных мы не можем выбрать априорное распределение, с которым будет проводиться сравнение, поэтому для симметричности оценки можно использовать сумму двух мер от P до Q и от Q до P:
Когда мы убедились в стабильности модели, надо проверить, что уверенность модели в сформированных прогнозах соответствует моделируемым значениям целевого события. Для этого применяется калибровка. Здесь мы кратко остановимся на том, как она работает, подробности будут описаны в статье, которая выйдет чуть позже (stay tuned).
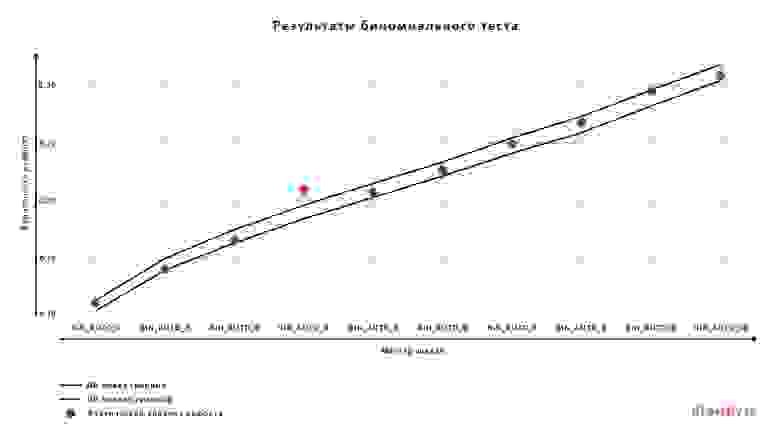
Модель считается хорошо откалиброванной, если фактический уровень целевого события (доля наблюдений с фактическим целевым событием = 1) близок к средней прогнозируемой моделью вероятности. Для оценки качества калибровки модели можно проверять попадание наблюдаемого уровня целевого события в доверительный интервал предсказанных моделью вероятностей целевого события: в целом по модели или в рамках бакетов предсказанной вероятности.
Примеры тестов и метрик:
Для проведения биномиального теста диапазон всех вероятностей целевого события разбивается на бакеты по принятой в финансовой организации шкале (мастер-шкале) или по перцентилям. Для каждого бакета рассчитывается доверительный интервал по предсказаниям модели и определяется, попадает ли фактический уровень дефолта в доверительный интервал.
Для формирования итогового решения о стратегии взаимодействия с клиентом может возникнуть необходимость определять разряд по заранее заданной шкале на основе значения вероятности дефолта, спрогнозированного моделью. В таком случае стоит проверить, что в распределении наблюдений по разрядам рейтинговой шкалы отсутствует перекос. Иными словами, чтобы предотвратить попадание большинства всех наблюдений в один-два разряда из всего набора.

Для проверки концентрации используется индекс Херфиндаля–Хиршмана как в целом по выборке, так и в разрезе отдельных сегментов.
Рассчитывается по формуле:
Подводя итог этого раздела, приведем пример пороговых значений метрик валидации моделей бинарной классификации и соответствующие им риск-зоны. В таблице для каждой метрики указаны пороговые значения риск-зон.

Мы перечислили тесты, применимые к моделям в разных доменных областях. Но могут быть метрики, которые отражают специфику конкретного продукта. Например, при моделировании операционных рисков может быть установлено дополнительное ограничение, связанное с пропускной способностью подразделения, проводящего расследования по признанным моделью подозрительными наблюдениям. После того как модель присвоила скоры всем пользователям, топ 1% или 5% пользователей по скору передается для проверки такому подразделению, другие пользователи не будут проверяться. Поэтому необходимо, чтобы максимальное число клиентов с y_true=1 попали в топ 1% или топ 5%.
Также для отдельных моделей могут быть предусмотрены специфические тесты. Например, для LGD-моделей Loss Shortfall.
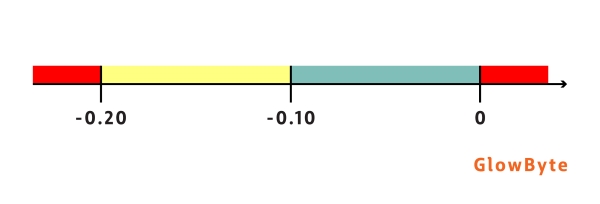
Loss Shortfall – метрика, указывающая, насколько потери от фактического дефолта оказались ниже, чем было предсказано моделью (методика расчета описана в [3]). По шкале выставления оценки для метрики Loss Shortfall видно (см. рисунок ниже), что оценка риска в данном случае производится консервативно, модель считается хорошей только в тех случаях, когда предсказанные потери выше, чем наблюдаемые.
Качественные тесты
Не все аспекты качества модели можно оценить количественно, поэтому вместе с ними при валидации применяются качественные тесты. Что можно проверять с их помощью?
1. Качество документации модели. Для обеспечения воспроизводимости модели необходима хорошая документация.
Оценить качество документации можно, определив, насколько хорошо задокументированы:
2. Дополнительно можно проверить качество использованных при разработке данных:
Заказчик может дополнительно запросить интерпретацию модели: если это регрессионная модель, то коэффициенты факторов; если decision tree/decision list, то набор правил; если более сложные модели, то отчет интерпретаторов SHAP/LIME.
Эта информация поможет пройти приемку модели, поскольку наглядно показывает, что все важные фичи, на которых модель делает выводы, подкреплены бизнес-логикой.
Model performance predictor (MPP)
В определенных задачах бывает необходимо прогнозировать события, которые произойдут спустя месяцы. Например, клиент не выполнит свои обязательства по кредитному договору в течение года. Из-за этого лага возникает проблема: как понять, что модель стала хуже работать, до того как мы сможем увидеть это, до получения фактических значений целевого события?

Для решения такой проблемы наряду с основной строится дополнительная модель — Model Performance Predictor (MPP) [6].
Схема обучения MPP-модели

Для разработки MPP-модели используется тестовая выборка основной модели. Шаги по построению MPP-модели.
Заключение
В завершение сформулируем принципы, которые гарантируют, что валидация модели будет эффективна:
Бинарное целевое событие:
| Тест | Блок | Виды тестирования по уровню «модель/фактор» | Дополнительные уровни тестирования |
| Джини индекс: абсолютное значение | Предсказательная способность | На уровне модели / факторов | По всей выборке / на уровне сегментов |
| Тест Колмогорова–Смирнова | Предсказательная способность | На уровне модели | По всей выборке / на уровне сегментов |
| IV | Предсказательная способность | На уровне факторов | По всей выборке / на уровне сегментов |
| Тест хи-квадрат | Калибровка | На уровне модели | По всей выборке |
| Биномиальный тест | Калибровка | На уровне модели | По всей выборке |
| Джини индекс: изменение | Стабильность | На уровне модели | Абсолютное / относительное изменение относительно предыдущего среза |
| PSI | Стабильность | На уровне модели / факторов | По всей выборке / на уровне сегментов |
| Тест Колмогорова–Смирнова | Стабильность | На уровне факторов | По всей выборке / на уровне сегментов |
| Индекс Херфиндаля–Хиршмана | Концентрация | На уровне модели | По всей выборке / на уровне сегментов |
| VIF | Дополнительно | На уровне факторов для линейных моделей | По всей выборке |
| Парная корреляция | Дополнительно | На уровне факторов для линейных моделей | По всей выборке |
| Значимость факторов (p-value) | Дополнительно | На уровне факторов для линейных моделей | По всей выборке |
| Тест | Блок | Виды тестирования по уровню «модель/фактор» | Дополнительные уровни тестирования |
| Джини индекс (Loss Capture Ratio): абсолютное значение | Предсказательная способность | На уровне модели / факторов | По всей выборке / на уровне сегментов |
| Корреляция Спирмена: абсолютное значение | Предсказательная способность | На уровне модели / факторов | По всей выборке / на уровне сегментов |
| MAE | Калибровка | На уровне модели | По всей выборке |
| Тест Манна–Уитни | Калибровка | На уровне модели | По всей выборке |
| Джини индекс (Loss Capture Ratio): изменение | Стабильность | На уровне модели | Абсолютное / относительное изменение относительно предыдущего среза |
| Корреляция Спирмена: изменение | Стабильность | На уровне модели | Абсолютное / относительное изменение относительно предыдущего среза |
| PSI | Стабильность | На уровне модели / факторов | По всей выборке / на уровне сегментов |
| Тест Колмогорова–Смирнова | Стабильность | На уровне факторов | По всей выборке / на уровне сегментов |
| VIF | Дополнительно | На уровне факторов для линейных моделей | По всей выборке |
| Парная корреляция | Дополнительно | На уровне факторов для линейных моделей | По всей выборке |
| Значимость факторов (p-value) | Дополнительно | На уровне факторов для линейных моделей | По всей выборке |
Материал подготовили: Илья Могильников (EienKotowaru), Александр Бородин (abv_gbc)



