Машинное обучение — это легко
Для кого эта статья?
Каждый, кому будет интересно затем покопаться в истории за поиском новых фактов, или каждый, кто хотя бы раз задавался вопросом «как же все таки это, машинное обучение, работает», найдёт здесь ответ на интересующий его вопрос. Вероятнее всего, опытный читатель не найдёт здесь для себя ничего интересного, так как программная часть оставляет желать лучшего несколько упрощена для освоения начинающими, однако осведомиться о происхождении машинного обучения и его развитии в целом не помешает никому.

В цифрах
С каждым годом растёт потребность в изучении больших данных как для компаний, так и для активных энтузиастов. В таких крупных компаниях, как Яндекс или Google, всё чаще используются такие инструменты для изучения данных, как язык программирования R, или библиотеки для Python (в этой статье я привожу примеры, написанные под Python 3). Согласно Закону Мура (а на картинке — и он сам), количество транзисторов на интегральной схеме удваивается каждые 24 месяца. Это значит, что с каждым годом производительность наших компьютеров растёт, а значит и ранее недоступные границы познания снова «смещаются вправо» — открывается простор для изучения больших данных, с чем и связано в первую очередь создание «науки о больших данных», изучение которого в основном стало возможным благодаря применению ранее описанных алгоритмов машинного обучения, проверить которые стало возможным лишь спустя полвека. Кто знает, может быть уже через несколько лет мы сможем в абсолютной точности описывать различные формы движения жидкости, например.
Анализ данных — это просто?
Да. А так же интересно. Наряду с особенной важностью для всего человечества изучать большие данные стоит относительная простота в самостоятельном их изучении и применении полученного «ответа» (от энтузиаста к энтузиастам). Для решения задачи классификации сегодня имеется огромное количество ресурсов; опуская большинство из них, можно воспользоваться средствами библиотеки Scikit-learn (SKlearn). Создаём свою первую обучаемую машину:
Вот мы и создали простейшую машину, способную предсказывать (или классифицировать) значения аргументов по их признакам.
— Если все так просто, почему до сих пор не каждый предсказывает, например, цены на валюту?
С этими словами можно было бы закончить статью, однако делать я этого, конечно же, не буду (буду конечно, но позже) существуют определенные нюансы выполнения корректности прогнозов для поставленных задач. Далеко не каждая задача решается вот так легко (о чем подробнее можно прочитать здесь)
Ближе к делу
— Получается, зарабатывать на этом деле я не сразу смогу?
Итак, сегодня нам потребуются:
Дальнейшее использование требует от читателя некоторых знаний о синтаксисе Python и его возможностях (в конце статьи будут представлены ссылки на полезные ресурсы, среди них и «основы Python 3»).
Как обычно, импортируем необходимые для работы библиотеки:
— Ладно, с Numpy всё понятно. Но зачем нам Pandas, да и еще read_csv?
Иногда бывает удобно «визуализировать» имеющиеся данные, тогда с ними становится проще работать. Тем более, большинство датасетов с популярного сервиса Kaggle собрано пользователями в формате CSV.
— Помнится, ты использовал слово «датасет». Так что же это такое?
Датасет — выборка данных, обычно в формате «множество из множеств признаков» → «некоторые значения» (которыми могут быть, например, цены на жильё, или порядковый номер множества некоторых классов), где X — множество признаков, а y — те самые некоторые значения. Определять, например, правильные индексы для множества классов — задача классификации, а искать целевые значения (такие как цена, или расстояния до объектов) — задача ранжирования. Подробнее о видах машинного обучения можно прочесть в статьях и публикациях, ссылки на которые, как и обещал, будут в конце статьи.
Знакомимся с данными
Предложенный датасет можно скачать здесь. Ссылка на исходные данные и описание признаков будет в конце статьи. По представленным параметрам нам предлагается определять, к какому сорту относится то или иное вино. Теперь мы можем разобраться, что же там происходит:
Работая в Jupyter notebook, получаем такой ответ:

Это значит, что теперь нам доступны данные для анализа. В первом столбце значения Grade показывают, к какому сорту относится вино, а остальные столбцы — признаки, по которым их можно различать. Попробуйте ввести вместо data.head() просто data — теперь для просмотра вам доступна не только «верхняя часть» датасета.
Простая реализация задачи на классификацию
Переходим к основной части статьи — решаем задачу классификации. Всё по порядку:
Создаем массивы, где X — признаки (с 1 по 13 колонки), y — классы (0ая колонка). Затем, чтобы собрать тестовую и обучающую выборку из исходных данных, воспользуемся удобной функцией кросс-валидации train_test_split, реализованной в scikit-learn. С готовыми выборками работаем дальше — импортируем RandomForestClassifier из ensemble в sklearn. Этот класс содержит в себе все необходимые для обучения и тестирования машины методы и функции. Присваиваем переменной clf (classifier) класс RandomForestClassifier, затем вызовом функции fit() обучаем машину из класса clf, где X_train — признаки категорий y_train. Теперь можно использовать встроенную в класс метрику score, чтобы определить точность предсказанных для X_test категорий по истинным значениям этих категорий y_test. При использовании данной метрики выводится значение точности от 0 до 1, где 1 100% Готово!
— Неплохая точность. Всегда ли так получается?
Для решения задач на классификацию важным фактором является выбор наилучших параметров для обучающей выборки категорий. Чем больше, тем лучше. Но не всегда (об этом также можно прочитать подробнее в интернете, однако, скорее всего, я напишу об этом ещё одну статью, рассчитанную на начинающих).
— Слишком легко. Больше мяса!
Для наглядного просмотра результата обучения на данном датасете можно привести такой пример: оставив только два параметра, чтобы задать их в двумерном пространстве, построим график обученной выборки (получится примерно такой график, он зависит от обучения):
Да, с уменьшением количества признаков, падает и точность распознавания. И график получился не особенно-то красивым, но это и не решающее в простом анализе: вполне наглядно видно, как машина выделила обучающую выборку (точки) и сравнила её с предсказанными (заливка) значениями.
Предлагаю читателю самостоятельно узнать почему и как он работает.
Последнее слово
Надеюсь, данная статья помогла хоть чуть-чуть освоиться Вам в разработке простого машинного обучения на Python. Этих знаний будет достаточно, чтобы продолжить интенсивный курс по дальнейшему изучению BigData+Machine Learning. Главное, переходить от простого к углубленному постепенно. А вот полезные ресурсы и статьи, как и обещал:
Материалы, вдохновившие автора на создание данной статьи
Более углубленное изучение использования машинного обучения с Python стало возможным, и более простым благодаря преподавателям с Яндекса — этот курс обладает всеми необходимыми средствами объяснения, как же работает вся система, рассказывается подробнее о видах машинного обучения итд.
Файл сегодняшнего датасета был взят отсюда и несколько модифицирован.
Где брать данные, или «хранилище датасетов» — здесь собрано огромное количество данных от самых разных источников. Очень полезно тренироваться на реальных данных.
Буду признателен за поддержку по улучшению данной статьи, а так же готов к любому виду конструктивной критики.
Простыми словами: как работает машинное обучение
В последнее время все технологические компании твердят о машинном обучении, но как оно работает, никто не рассказывает. А мы расскажем — максимально простыми словами.


В последнее время все технологические компании твердят о машинном обучении. Мол, столько задач оно решает, которые раньше только люди и могли решить. Но как конкретно оно работает, никто не рассказывает. А кто-то даже для красного словца машинное обучение называет искусственным интеллектом.
Как обычно, никакой магии тут нет, все одни технологии. А раз технологии, то несложно все это объяснить человеческим языком, чем мы сейчас и займемся. Задачу мы будем решать самую настоящую. И алгоритм будем описывать настоящий, подпадающий под определение машинного обучения. Сложность этого алгоритма игрушечная — а вот выводы он позволяет сделать самые настоящие.
Задача: отличить осмысленный текст от белиберды
Текст, который пишут настоящие люди, выглядит так:
Могу творить, могу и натворить!
У меня два недостатка: плохая память и что-то еще.
Никто не знает столько, сколько не знаю я.
Белиберда выглядит так:
ОРПорыав аоырОрпаыор ОрОРАыдцуцзущгкгеуб ыватьыивдцулвдлоадузцщ
Йцхяь длваополц ыадолцлопиолым бамдлотдламда.
Наша задача — разработать алгоритм машинного обучения, который бы отличал одно от другого. А поскольку мы говорим об этом применительно к антивирусной тематике, то будем называть осмысленный текст «чистым», а белиберду — «зловредной». Это не просто какой-то мысленный эксперимент, похожая задача на самом деле решается при анализе реальных файлов в реальном антивирусе.
Для человека задача кажется тривиальной, ведь сразу видно, где чистое, а где зловредное, но вот формализовать разницу или тем более объяснить ее компьютеру — уже сложнее. Мы используем машинное обучение: сначала дадим алгоритму примеры, он на них «обучится», а потом будет сам правильно отвечать, где что.
Алгоритм
Наш алгоритм будет считать, как часто в нормальном тексте одна конкретная буква следует за другой конкретной буквой. И так для каждой пары букв. Например, для первой чистой фразы — «Могу творить, могу и натворить!» — распределение получится такое:
ат — 1
во — 2
гу — 2
ит — 2
мо — 2
на — 1
ог — 2
ор — 2
ри — 2
тв — 2
ть — 2
Что получилось: за буквой «в» следует буква «о» — два раза, а за буквой «а» следует буква «т» — один раз. Для простоты мы не учитываем знаки препинания и пробелы.
На этом этапе мы понимаем, что для обучения нашей модели одной фразы мало: и сочетаний недостаточное количество, и разница между частотой появления разных сочетаний не так велика. Поэтому надо взять какой-то существенно больший объем данных. Например, давайте посчитаем, какие сочетания букв встречаются в первом томе «Войны и мира»:
то — 8411
ст — 6591
на — 6236
го — 5639
ал — 5637
ра — 5273
не — 5199
по — 5174
ен — 4211
оу — 31
мб — 2
тж — 1
Разумеется, это не вся таблица сочетаний, а лишь ее малая часть. Оказывается, вероятность встретить «то» в два раза выше, чем «ен«. А чтобы за буквой «т» следовала «ж» — такое встречается лишь один раз, в слове «отжившим».
Отлично, «модель» русского языка у нас теперь есть, как же ее использовать? Чтобы определить, насколько вероятно исследуемая нами строка чистая или зловредная, посчитаем ее «правдоподобность». Мы будем брать каждую пару букв из этой строки, определять по «модели» ее частоту (по сути, реалистичность сочетания букв) и перемножать эти числа:
Также в финальном значении правдоподобности следует учесть количество символов в исследуемой строке — ведь чем она была длиннее, тем больше чисел мы перемножили. Поэтому из произведения извлечем корень нужной степени (длина строки минус один).
Использование модели
Теперь мы можем делать выводы: чем больше полученное число — тем правдоподобнее исследуемая строка ложится в нашу модель. Стало быть, тем больше вероятность, что ее писал человек, то есть она чистая.
Если же исследуемая строка содержит подозрительно большое количество крайне редких сочетаний букв (например, «ёё», «тж», «ъь» и так далее), то, скорее всего, она искусственная — зловредная.
Для строчек выше правдоподобность получилась следующая:
Могу творить, могу и натворить! — 1805 баллов
У меня два недостатка: плохая память и что-то еще. — 1535 баллов
Никто не знает столько, сколько не знаю я. — 2274 балла
ОРПорыав аоырОрпаыор ОрОРАыдцуцзущгкгеуб ыватьыивдцулвдлоадузцщ — 44 балла
Йцхяь длваополц ыадолцлопиолым бамдлотдламда — 149 баллов
Как видите, чистые строки правдоподобны на 1000–2000 баллов, а зловредные недотягивают и до 150. То есть все работает так, как задумано.
Чтобы не гадать, что такое «много», а что — «мало», лучше доверить определение порогового значения самой машине (пусть обучается). Для этого скормим ей некоторое количество чистых строк и посчитаем их правдоподобность, а потом скормим немного зловредных строк — и тоже посчитаем. И вычислим некоторое значение посередине, которое будет лучше всего отделять одни от других. В нашем случае получится что-то в районе 500.
В реальной жизни
Давайте осмыслим, что же у нас получилось.
1. Мы выделили признаки чистых строк, а именно пары символов.
В реальной жизни — при разработке настоящего антивируса — тоже выделяют признаки из файлов или других объектов. И это, кстати, самый важный шаг: от уровня экспертизы и опыта исследователей напрямую зависит качество выделяемых признаков. Понять, что же на самом деле важно, — это все еще задача человека. Например, кто сказал, что надо использовать пары символов, а не тройки? Такие гипотезы как раз и проверяют в антивирусной лаборатории. Отмечу, что у нас для отбора наилучших и взаимодополняющих признаков тоже используется машинное обучение.
2. На основании выделенных признаков мы построили математическую модель и обучили ее на примерах.
Само собой, в реальной жизни мы используем модели чуть посложнее. Сейчас наилучшие результаты показывает ансамбль решающих деревьев, построенный методом Gradient boosting, но стремление к совершенству не позволяет нам успокоиться.
3. На основе математической модели мы посчитали рейтинг «правдоподобности».
В реальной жизни мы обычно считаем противоположный рейтинг — рейтинг вредоносности. Разница, казалось бы, несущественная, но угадайте, насколько неправдоподобной для нашей математической модели покажется строка на другом языке или с другим алфавитом. Антивирус не имеет права допустить ложное срабатывание на целом классе файлов только по той причине, что «мы его не проходили».
Альтернатива машинному обучению
20 лет назад, когда вредоносов было мало, каждую «белиберду» можно было просто задетектить с помощью сигнатур — характерных отрывков. Для примеров выше «сигнатуры» могли бы быть такими:
ОРПорыав аоырОрпаыор ОрОРАыдцуцзущгкгеуб ыватьыивдцулвдлоадузцщ
Йцхяь длваополц ыадолцлопиолым бамдлотдламда
Антивирус сканирует файл, если встретил «зущгкгеу«, говорит: «Ну понятно, это белиберда номер 17». А если найдет «длотдламд» — то «белиберда номер 139».
15 лет назад, когда вредоносов стало много, преобладать стало «дженерик»-детектирование. Вирусный аналитик пишет правила, что для осмысленных строк характерно:
По существу, это примерно то же самое, только вместо математической модели в этом случае набор правил, которые аналитик должен вручную написать. Это хорошо работает, но требует времени.
И вот 10 лет назад, когда вредоносов стало ну просто очень много, начали робко внедряться алгоритмы машинного обучения. Поначалу по сложности они были сопоставимы с описанным нами простейшим примером, но мы активно нанимали специалистов и наращивали экспертизу. Как итог — у нас лучший уровень детектирования.
Сейчас без машинного обучения не работает ни один нормальный антивирус. Если оценивать вклад в защиту пользователей, то с методами на основе машинного обучения по статическим признакам могут посоперничать разве что методы на основе анализа поведения. Но только при анализе поведения тоже используется машинное обучение. В общем, без него уже никуда.
Недостатки
Преимущества понятны, но неужели это серебряная пуля, спросите вы. Не совсем. Этот метод хорошо справляется, если описанный выше алгоритм будет работать в облаке или в инфраструктуре, постоянно обучаясь на огромных количествах как чистых, так и вредоносных объектов.
Также очень хорошо, если за результатами обучения присматривает команда экспертов, вмешивающихся в тех случаях, когда без опытного человека не обойтись.
В этом случае недостатков действительно немного, а по большому счету только один — нужна эта дорогостоящая инфраструктура и не менее дорогостоящая команда специалистов.
Другое дело, когда кто-то пытается радикально сэкономить и использовать только математическую модель и только на стороне продукта, прямо у клиента. Тогда могут начаться трудности.
1. Ложные срабатывания.
Детектирование на базе машинного обучения — это всегда поиск баланса между уровнем детектирования и уровнем ложных срабатываний. И если нам захочется детектировать побольше, то ложные срабатывания будут. В случае машинного обучения они будут возникать в непредсказуемых и зачастую труднообъяснимых местах. Например, эта чистая строка — «Мцыри и Мкртчян» — распознается как неправдоподобная: 145 баллов в модели из нашего примера. Поэтому очень важно, чтобы антивирусная лаборатория имела обширную коллекцию чистых файлов для обучения и тестирования модели.
Злоумышленник может разобрать такой продукт и посмотреть, как работает модель. Он человек и пока если не умнее, то хотя бы креативнее машины — поэтому он подстроится. Например, следующая строка считается чистой (1200 баллов), хотя ее первая половина явно вредоносная: «лоыралоыврачигшуралорыловарДобавляем в конец много осмысленного текста, чтобы обмануть машину». Какой бы умный алгоритм ни использовался, его всегда может обойти человек (достаточно умный). Поэтому антивирусная лаборатория обязана иметь продвинутую инфраструктуру для быстрой реакции на новые угрозы.

Один из примеров обхода описанного нами выше метода: все слова выглядят правдоподобно, но на самом деле это бессмыслица. Источник
3. Обновление модели.
На примере описанного выше алгоритма мы упоминали, что модель, обученная на русских текстах, будет непригодна для анализа текстов с другим алфавитом. А вредоносные файлы, с учетом креативности злоумышленников (смотри предыдущий пункт), — это как будто постепенно эволюционирующий алфавит. Ландшафт угроз меняется довольно быстро. Мы за долгие годы исследований выработали оптимальный подход к постепенному обновлению модели прямо в антивирусных базах. Это позволяет дообучать и даже полностью переобучать модель «без отрыва от производства».
Заключение
Несмотря на огромную важность машинного обучения в сфере кибербезопасности, мы в «Лаборатории Касперского» понимаем, что лучшую в мире киберзащиту обеспечивает именно многоуровневый подход.
Все в антивирусе должно быть прекрасно — и поведенческий анализ, и облачная защита, и алгоритмы машинного обучения, и многое-многое другое. Но об этом «многом другом» — в следующий раз.
Что такое Machine Learning и каким оно бывает
Что такое машинное обучение
Machine Learning (ML, с английского – машинное обучение) — это методики анализа данных, которые позволяют аналитической системе обучаться в ходе решения множества сходных задач. Машинное обучение базируется на идее о том, что аналитические системы могут учиться выявлять закономерности и принимать решения с минимальным участием человека.
Давайте представим, что существует программа, которая может проанализировать погоду за прошедшую неделю, а также показания термометра, барометра и анемометра (ветрометра), чтобы составить прогноз. 10 лет назад для этого написали бы алгоритм с большим количеством условных конструкций If (если):
От программиста требовалось описать невероятное количество условий, чтобы код мог предсказывать изменение погоды. В лучшем случае использовался многомерный анализ данных, но и в нем все закономерности указывались вручную. Но даже если такую программу называли искусственным интеллектом, это была лишь имитация.

Большая часть программ с искусственным интеллектом на самом деле состоит из условных конструкций
Машинное обучение же позволяет дать программе возможность самостоятельно строить причинно-следственные связи. ИИ получает задачу и сам учится ее решать. То есть компьютер может проанализировать показатели за несколько месяцев или даже лет, чтобы определить, какие факторы оказывали влияние на изменение погоды.
Вот хороший пример от гугловского DeepMind:

DeepMind от Google самостоятельно научился ходить
Программа получала информацию от виртуальных рецепторов, а ее целью было перевести модель из точки А в точку Б. Никаких инструкций по этому поводу не было – разработчики лишь создали алгоритм, по которому программа обучалась. В результате она смогла самостоятельно выполнить задачу.
ИИ, словно ребенок, пробовал разные методы, чтобы найти тот, который лучше всего поможет добиться результата. Также он учитывал особенности моделей, заставляя четвероногую прыгать, человекообразную – бежать. Также ИИ смог балансировать на двигающихся плитах, обходить препятствия и перемещаться по бездорожью.
Для чего используется машинное обучение
В примере выше описывалась ходьба – это поможет человечеству создавать обучаемых роботов, которые смогут адаптироваться, чтобы выполнять поставленные задачи. Например, тушить пожары, разбирать завалы, добывать руду и так далее. В этих случаях машинное обучение гораздо эффективнее, чем обычная программа, потому что человек может допустить ошибку во время написания кода, из-за чего робот может впасть в ступор, потому что не знает, как взаимодействовать с камнем той формы, которую не прописал разработчик.
Но до этого пройдет еще несколько лет или даже десятилетий. А что же сейчас? Разве машинное обучение еще не начали использовать для решения практических задач? Начали, технология широко используется в области data science (науки о данных). И чаще всего эти задачи маркетинговые.
Amazon использует ИИ с машинным обучением, чтобы предлагать пользователям тот товар, который они купят с наибольшей вероятностью. Для этого программа анализирует опыт других пользователей, чтобы применить его к новым. Но пока у системы есть свои недостатки – купив однажды шапку, пользователь будет видеть предложения купить еще. Программа сделает вывод, что раз была нужна одна шапка, то и несколько сотен других не повредят.
Похожую систему использует Google, чтобы подбирать релевантную рекламу, и у него такие же проблемы – стоит поискать информацию о том, какие виды велосипедов бывают, как Google тут же решит, что пользователь хочет погрузиться в эту тему с головой. Тем же самым занимается и «Яндекс» в своем сервисе «Дзен» – там МО используется для формирования ленты, точно так же, как и в Twitter, Instagram, Facebook, «ВКонтакте» и других социальных сетях.
Вы также могли работать с голосовыми помощниками вроде Siri – они используют системы распознавания речи, основанные на ML. В будущем они могут заменить секретарей и операторов кол-центров. Если вы загорелись этой идеей, можете попробовать сервис аудиоаналитики Sounds от VK.
Есть и другие примеры использования систем с машинным обучением:
То есть применение МО может быть самым разным. И даже вы можете использовать его в своих приложениях – для этого понадобится приобрести, настроить и поддерживать инфраструктуру обучения машинных моделей. Альтернатива — воспользоваться готовыми средствами машинного обучения на платформе VK Cloud Solutions (бывш. MCS).
Краткое введение в Машинное обучение
Пару лет назад я рассказывал жене сказки, что когда я буду старым маразматиком, мое ближайшее окружение не будет страдать от этого, ведь за мной будут ухаживать роботы. Новости о прогрессе искусственного интеллекта впечатляли меня (нейросетки то, нейросетки сё), свет в конце тоннеля манил, как и зарплаты специалистов в этой области. Разумеется, я не смог пройти мимо и решил погрузиться в Machine Learning.
Для старта хотелось почитать что-то совсем базовое, но поиск по строкам «машинное обучение для чайников» вменяемых результатов не дал. Все статьи начинались с тривиальных рассуждений, а потом перепрыгивали на загадочные формулы без особых пояснений. Я не сдавался и добыл несколько книг с хорошими отзывами, но получил то же самое, только уже на 600 страниц. Спустя полгода поисков могу сообщить вам следующее: при текущих темпах развития AI я не увижу роботов в старости, для работы с Machine Learning на самом деле не нужна математика, и как минимум одна статья «машинное обучение для чайников» существует, вы ее сейчас читаете.
Итак, ознакомившись с этой статьей вы поймете, что вообще представляет собой группа технологий ML. Имея эту базу вам будет проще двигаться дальше, и даже формулы в книгах станут понятнее. Раз уж зашел разговор о книгах, то сразу порекомендую ту, с которой у меня начался реальный прогресс: Andrew Glassner, «DEEP LEARNING: From Basics to Practice». В русском варианте она называется «Глубокое обучение без математики»: автор разжевывает алгоритмы не прибегая к формулам. После томов, полных математического пафоса, это был просто глоток свежего воздуха. Еще один важный момент: постарайтесь читать англоязычную литературу, т.к. перевод терминов на русский язык местами сильно страдает. Человеку, который ввел фразу «Обучение с учителем» должно быть очень стыдно.
Создадим модель и обучим ее
Начнем с классики жанра: у нас есть база данных недвижимости с десятком атрибутов (стоимость, площадь, количество комнат и т.д.), на ее основе надо научиться предсказывать стоимость других домов. Тут вы скажете: «Стопэ! Нам надо нейросетку, которая убирает купальники с фотографий, а ты пихаешь нам примитивную задачу о расчете усредненной стоимости!». Я поначалу тоже был в шоке, что эти задачи являются существенной частью ML. И я пришел в ужас от того, что в ML распознавание объектов на фотографии работает по такому же принципу, что и наше предсказание стоимости. Тут ключевое слово «Работает», так что давайте продолжим, сейчас все станет понятно.
Задача сводится к двум шагам: выбрать модель (подобрать подходящую формулу расчета) и затем найти ее коэффициенты. Модель для нашего примера возьмем упрощенную:

Теперь мы будем перебирать значения коэффициентов A до тех пор, пока уровень ошибки не станет приемлемым, это и называется Обучением модели.
Ошибку каждый раз вычисляем, конечно же, по нашей базе данных (Обучающей выборке, Training Set), алгоритм очень простой: для каждого дома находим разницу между расчетной и фактической стоимостью, возводим разницу в квадрат (чтобы избавиться от отрицательных чисел) и находим среднее значение всех этих отклонений. Формула для вычисления ошибки называется Функцией потерь (Loss Function), описанный алгоритм расчета популярный, но не единственный.
Если ошибку не удается снизить до вменяемых значений, значит мы неудачно выбрали модель: возможно, надо количество комнат брать в квадрат, или Удаленность от центра не плюсовать, а делить. Вариантов много, математики не могут ответить на вопрос «Как выбрать модель», поэтому просто сидим и пробуем разные, пока не получится (тут становятся понятны некоторые шутки про Data Scientist-ов).
А что насчет распознавания объектов на фотографиях? Идея простая: если сделать огромную формулу, которая на вход принимает миллион значений (пиксели фотографии) и внутри имеет сотню тысяч коэффициентов, то после удачного «обучения» она начнет на выходе выдавать «Вероятность наличия собаки на фото» (значение от 0.0 до 1.0). И это прокатило, такие формулы действительно работают, это называют Глубоким обучением (Deep Learning). Есть две сложности: формулу такого размера руками не написать, а ее коэффициенты даже на супер-компьютере методом простого перебора не вычислить. Приступаем к оптимизации.
Перцептрон и Нейронная сеть
В книгах вы прочитаете, что идея создания Перцептрона была навеяна структурой нашего мозга (нейронами), но сходство там очень отдаленное. Перцептрон работает гораздо проще, это всего лишь графическое представление обычного линейного уравнения:


Всего одной строкой мы рассчитали стоимости всех домов в нашей базе: в одномерный массив W закидываем все веса перцептрона, в двумерный массив X помещаем всю базу недвижимости (кроме стоимости), а в выходном одномерном массиве Y получаем все рассчитанные стоимости. Но краткостью записи все достоинства матриц и заканчиваются. С вычислительной точки зрения здесь нет никакого ускорения (если вы конечно пишите не на Python), а сама операция сведется к трем вложенным циклам с расчетом все того же линейного уравнения. Отказ от матриц, напротив, дает больше пространства для маневра и оптимизаций, но это повод для отдельной статьи.
На практике вам не придется работать с матрицами, готовые библиотеки избавят вас от этой мороки, так что кроме как в книгах вы эти матричные формулы больше нигде не увидите (ну еще в статьях на Хабре).
На одном линейном уравнении далеко не уедешь, пока что наша модель не сможет корректно предсказать стоимость, не говоря уже о собаке на фото:
Для большей гибкости перцептроны объединяют в нейронные сети (на таких рисунках не показывают Веса, но свой набор есть у каждого перцептрона в сети):
Тут нас ждет сюрприз: какие бы сложные комбинации связей мы ни рисовали, в итоге получим наше исходное линейное уравнение. Ни одно из входных значений x не будет возведено в степень, т.к. перцептроны соединяются между собой через операцию Сложения. Чтобы как-то исправить ситуацию на выходе каждого перцептрона добавили Функцию активации (Activation function):
Эта функция Ψ обязательно нелинейная, конечно же есть популярные варианты, которые вы найдете в любой книге (рисунки с Wikipedia):
Какую функцию использовать в вашей модели? Математики также не могут ответить на этот вопрос, пробуйте разные и смотрите что лучше работает в вашем случае. Сигмоид относительно требователен к вычислительным ресурсам, поэтому его чаще ставят только на выходе нейросети, чтобы получить красивое значение от 0.0 до 1.0 (именно для красоты, на выходе он не влияет на работу сети). Говорят, что и обычный Косинус работает неплохо (если таки углубиться в математику и взглянуть на Ряд Фурье, то возникает ощущение, что именно им и надо пользоваться, но я сам пока не пробовал). Для полного понимания работы функций активации давайте взглянем, во что превратилось уравнение нашего перцептрона в случае Сигмоида:

Наша модель выглядит сложнее, а если попытаться нарисовать формулу для всей нейронной сети, то будет вообще мясо, даже в матричном виде ее уже не пытаются изобразить. Благодаря функциям активации гибкость достигнута.
Как разработчику, вам не потребуется прописывать все эти формулы, готовые библиотеки избавят вас и от этой мороки. Есть теорема, которая доказывает, что с помощью линейных уравнений с функциями активации можно смоделировать любой процесс. Теорема правда не говорит, сколько весов должно быть в модели и как долго вы ее будете обучать.
Обучение модели
Простой перебор весов займет очень длительное время, т.к. после любой их корректировки надо прогонять через нейронную сеть всю обучающую выборку, чтобы посмотреть, как изменилась ошибка. Здесь нам помогут два метода: Градиентный спуск (Gradient Descent) и в дополнение к нему Обратное распространение (Backpropagation). Детальное вменяемое описание работы этой пары вы найдете все в той же книге «DEEP LEARNING: From Basics to Practice», а я приведу только самую суть.
Шаг 1: после создания нейронной сети проставляем начальные значения всем весам (обычно, маленькие случайные числа), прогоняем через нее обучающую выборку и вычисляем ошибку (Loss function). Если ошибка равна нулю, то Бог есть и он сегодня с вами. Все остальные пройдемте к шагу два.
Шаг 2: теперь нам надо поправить веса так, чтобы ошибка стала меньше. Взглянем, например, на вес W508, в какую сторону будем его двигать?
Для этого нам требуется производная от Функции потерь, что уже требует знаний математики (кажется 11 класс школы), но вас это не должно беспокоить, все производные для стандартных Функций потерь уже найдены и заботливо упакованы в библиотеки. Вам требуется только общее понимание, как это работает, чтобы суметь разобраться в причинах сбоев при обучении.
По градиенту мы видим не только в какую сторону менять вес, но и как сильно это делать (по крутизне наклона). По этой методике поочередно находим градиент для каждого веса и меняем их значения, это и есть Метод градиентного спуска.
Шаг 3: опять прогоняем обучающую выборку через сеть, вычисляем ошибку, вычисляем новые градиенты для весов:
И видим прогресс: ошибка действительно изменилась в меньшую сторону, а новый Градиент имеет меньший угол наклона, значит мы близки к минимальному значению ошибки на графике. Повторяем процесс до посинения тех пор, пока модель не перестанет обучаться, в этом случае градиенты станут почти горизонтальными линиями.
Какие есть подводные камни? А давайте все-таки построим полный график для Веса W508
Оказывается, мы шли не в том направлении, потому что начальное значение веса (случайное число) упало не в ту часть графика. Мы достигли, так называемого, локального минимума, и на графике их может быть очень много. Как с этим бороться? Запускаем обучение заново и надеемся, что в этот раз исходное случайное значение веса упадет в нужную область. Метод проб и ошибок все еще наш лучший друг.
А что там с Backpropagation? Вроде все посчитали, все работает, он нам зачем? Вычисление градиента для каждого из весов, описанное выше, относительно затратная процедура. Метод обратного распространения сильно упрощает этот процесс: зная градиент для правой части нейронной сети мы легко вычисляем градиенты для весов, находящихся левее. Двигаясь по сети все левее и левее мы постепенно обновляем все веса. Из-за этого движения справа налево метод и назвали «Обратным».
Таким образом, Backpropagation занимается только вычислением градиентов, а обновление весов по найденным градиентам выполняется с помощью Метода градиентного спуска. В реальной жизни часто упоминают только Backpropagation, опуская вторую составляющую, но вы должны понимать, что они идут в паре.
Виды нейронных сетей
Выше уже был показан вариант Полносвязной нейронной сети (Fully connected neural network), но они бывают еще и такими:
Кстати о картинках: в Полносвязную сеть пиксели изображения подаются построчно:
Это не очень-то логично, гораздо лучше близлежащие пиксели отправлять в нейросеть также рядышком:
Так и появились Сверточные нейронные сети (Convolutional neural network), или просто CNN. Это все еще набор перцептронов с функциями активации внутри, но набор связей между ними специфический, уже не все со всеми. Обучаются они все тем же методом Backpropagation.
Выделенную на рисунке цветом область называют «Фильтр». Обычно это квадрат со стороной 3-5 пикселей. Фильтр накладывают на изображение: значения x умножаем на веса и суммируем их, т.е. пропускаем значения через перцептрон. Результат сохраняем в новый двумерный массив. Далее снова накладываем этот же фильтр на изображение, но уже сдвинув его вправо на один пиксель (иногда используют большее смещение), и так пробегаем по всему изображению. Все это повторяем с другими фильтрами (еще несколько перцептронов с другими значениями весов), сохраняя результаты в отдельные массивы. Отфильтрованные изображения прогоняем еще через несколько фильтров, подвергаем дополнительным обработкам, и результат можно, например, подать на полносвязную сеть.
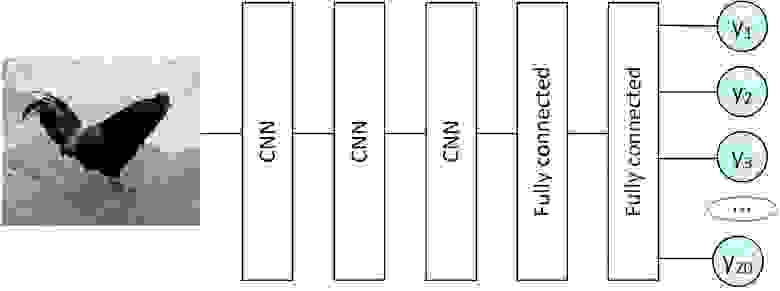
В литературе их часто называют нейросетями с памятью, но так можно сказать с очень большой натяжкой. Также в учебниках вы часто увидите попытку объяснить работу RNN через графы, но можно не забивать себе этим голову. Работают они очень просто:
В перцептрон добавилось Состояние (массив S): это переменные, в которых мы сохраняем результат вычисления всего перцептрона (домножив на веса), чтобы использовать их при следующем вызове перцептрона. При первом запуске Состояние заполняется нулями. Если вы уже распознали какой-то блок текста (например, e-mail) и готовы перейти к следующему независимому блоку данных, то Состояние принудительно обнуляется.
Если вы пытаетесь предсказать температуру на завтра, то такая нейросеть будет оперировать не только текущими показаниями (облачность, сила и направление ветра), но и предыдущим значением температуры, что очень логично.
Для Состояния есть несколько усложнений, которые повышают качество работы RNN. Если мы хотим учитывать не только последнее выходное значение, но и несколько предыдущих, то формула вычисления Состояния немного меняется (исходный код, не математическая формула):

Таким образом мы не полностью перезаписываем значение, а добавляем некоторое изменение, в зависимости от выходного значения.
Решаемые задачи
Алгоритмы машинного обучения подразделяют на «Обучение с учителем» (Supervised Learning, привет переводчику) и «Обучение без учителя» (Unsupervised Learning). Года два назад я был уверен, что речь идет о самообучаемых алгоритмах и о тех, за которыми надо присматривать. На самом деле здесь идет речь о двух группах:
Рассмотрим сами алгоритмы, начнем с Классификации, выше уже был пример: что находится на фото (кошка, собака и т.д.)? Другие классические примеры: является ли письмо спамом (бинарная классификация, т.к. ответ да/нет), распознавание букв и цифр на изображениях.
Генерация контента, можно выполнить с помощью Автокодировщика. Для этого используется специфическая нейронная сеть с «бутылочным горлышком»:
При обучении такую сеть заставляют на выходе генерировать точно такие же данные, что поступили на вход, например, в обучающую выборку включают разные фото травы. После завершения обучения сеть разрывают:
Теперь, подавая на вход пару чисел, на выходе мы можем получить совершенно новые изображения травы (либо белеберду, как повезет). Внутри Автокодировщика можно использовать полносвязные сети, CNN и RNN, а также любые их комбинации, важно только создать бутылочное горлышко.
За что же платят так много денег?
Как мы увидели выше, ничего особо сложного в Машинном обучении нет. Вся математика скрыта в недрах библиотек, количество алгоритмов ограничено, вариантов оптимизации не слишком много, сиди да подбирай коэффициенты случайным образом. Почему же зарплаты Data Scientist так высоки? Чтобы быть успешным в этом деле надо все-таки включать голову.
Успех складывается из двух вещей:
у вас есть очень много данных в обучающей выборке и очень мощные серверы для их обработки (тогда достаточно взять готовую GPT-3 и обучить ее русскому языку);
вы отлично знаете предметную область, в которой пытаетесь применить машинное обучение.
Меняя количество перцептронов в нейронной сети вы можете немного повысить качество ее работы, но настоящий прорыв возможен, если вы усовершенствуете алгоритм в целом. Например, декомпозируете задачу: с помощью первой нейронной сети преобразуем фотографию в простейшие фигуры (треугольник, круг, волнистые линии), а второй нейронкой определяем, что же там нарисовано.

Заключение
В этой статье я привел лишь самые базовые вещи. Есть еще огромное количество нюансов, которые вы почерпнете из книг и статей, но у вас теперь есть основной вектор движения.



