Поговорим за Hadoop

Введение
Как человеку с не очень устойчивой психикой, мне достаточно одного взгляда на картинку, подобную этой, для начала панической атаки. Но я решил, что страдать буду только сам. Цель статьи — сделать так, чтобы Hadoop выглядел не таким страшным.
Что будет в этой статье:
Чего не будет в этой статье:
Что такое Hadoop и зачем он нужен
Hadoop не так уж сложен, ядро состоит из файловой системы HDFS и MapReduce фреймворка для обработки данных из этой файловой системы.
Если смотреть на вопрос «зачем нам нужен Hadoop?» с точки зрения использования в крупном энтерпрайзе, то ответов достаточно много, причем варьируются они от «сильно за» до «очень против». Я рекомендую просмотреть статью ThoughtWorks.
Если смотреть на этот же вопрос уже с технической точки зрения — для каких задач нам есть смысл использовать Hadoop — тут тоже не все так просто. В мануалах в первую очередь разбираются два основных примера: word count и анализ логов. Ну хорошо, а если у меня не word count и не анализ логов?
Хорошо бы еще и определить ответ как-нибудь просто. Например, SQL — нужно использовать, если у вас есть очень много структурированных данных и вам очень хочется с данными поговорить. Задать как можно больше вопросов заранее неизвестной природы и формата.
Длинный ответ —просмотреть какое-то количество существующих решений и собрать неявным образом в подкорке условия, для которых нужен Hadoop. Можно ковыряться в блогах, могу еще посоветовать прочитать книгу Mahmoud Parsian «Data Algorithms: Recipes for Scaling up with Hadoop and Spark».
Попробую ответить короче. Hadoop следует использовать, если:
Архитектура HDFS и типичный Hadoop кластер
HDFS подобна другим традиционным файловым системам: файлы хранятся в виде блоков, существует маппинг между блоками и именами файлов, поддерживается древовидная структура, поддерживается модель доступа к файлам основанная на правах и т. п.
Hadoop-кластер состоит из нод трех типов: NameNode, Secondary NameNode, Datanode.
Namenode — мозг системы. Как правило, одна нода на кластер (больше в случае Namenode Federation, но мы этот случай оставляем за бортом). Хранит в себе все метаданные системы — непосредственно маппинг между файлами и блоками. Если нода 1 то она же и является Single Point of Failure. Эта проблема решена во второй версии Hadoop с помощью Namenode Federation.
Secondary NameNode — 1 нода на кластер. Принято говорить, что «Secondary NameNode» — это одно из самых неудачных названий за всю историю программ. Действительно, Secondary NameNode не является репликой NameNode. Состояние файловой системы хранится непосредственно в файле fsimage и в лог файле edits, содержащим последние изменения файловой системы (похоже на лог транзакций в мире РСУБД). Работа Secondary NameNode заключается в периодическом мерже fsimage и edits — Secondary NameNode поддерживает размер edits в разумных пределах. Secondary NameNode необходима для быстрого ручного восстанавления NameNode в случае выхода NameNode из строя.
В реальном кластере NameNode и Secondary NameNode — отдельные сервера, требовательные к памяти и к жесткому диску. А заявленное “commodity hardware” — уже случай DataNode.
DataNode — Таких нод в кластере очень много. Они хранят непосредственно блоки файлов. Нода регулярно отправляет NameNode свой статус (показывает, что еще жива) и ежечасно — репорт, информацию обо всех хранимых на этой ноде блоках. Это необходимо для поддержания нужного уровня репликации.
Посмотрим, как происходит запись данных в HDFS:
Клиент продолжает записывать блоки, если сумеет записать успешно блок хотя бы на одну ноду, т. е. репликация будет работать по хорошо известному принципу «eventual», в дальнейшем NameNode обязуется компенсировать и таки достичь желаемого уровня репликации.
Завершая обзор HDFS и кластера, обратим внимание на еще одну замечательную особенность Hadoop’а — rack awareness. Кластер можно сконфигурировать так, чтобы NameNode имел представление, какие ноды на каких rack’ах находятся, тем самым обеспечив лучшую защиту от сбоев.
MapReduce
Единица работы job — набор map (параллельная обработка данных) и reduce (объединение выводов из map) задач. Map-задачи выполняют mapper’ы, reduce — reducer’ы. Job состоит минимум из одного mapper’а, reducer’ы опциональны. Здесь разобран вопрос разбиения задачи на map’ы и reduce’ы. Если слова «map» и «reduce» вам совсем непонятны, можно посмотреть классическую статью на эту тему.
Модель MapReduce
Посмотрим на архитектуру MapReduce 1. Для начала расширим представление о hadoop-кластере, добавив в кластер два новых элемента — JobTracker и TaskTracker. JobTracker непосредственно запросы от клиентов и управляет map/reduce тасками на TaskTracker’ах. JobTracker и NameNode разносится на разные машины, тогда как DataNode и TaskTracker находятся на одной машине.
Взаимодействие клиента и кластера выглядит следующим образом:
1. Клиент отправляет job на JobTracker. Job представляет из себя jar-файл.
2. JobTracker ищет TaskTracker’ы с учетом локальности данных, т.е. предпочитая те, которые уже хранят данные из HDFS. JobTracker назначает map и reduce задачи TaskTracker’ам
3. TaskTracker’ы отправляют отчет о выполнении работы JobTracker’у.
Неудачное выполнение задачи — ожидаемое поведение, провалившиеся таски автоматически перезапускаются на других машинах.
В Map/Reduce 2 (Apache YARN) больше не используется терминология «JobTracker/TaskTracker». JobTracker разделен на ResourceManager — управление ресурсами и Application Master — управление приложениями (одним из которых и является непосредственно MapReduce). MapReduce v2 использует новое API
Настройка окружения
На рынке существуют несколько разных дистрибутивов Hadoop: Cloudera, HortonWorks, MapR — в порядке популярности. Однако мы заострять внимание на выборе конкретного дистрибутива не будем. Подробный анализ дистрибутивов можно найти здесь.
Есть два способа безболезненно и с минимальными трудозатратами попробовать Hadoop:
1. Amazon Cluster — полноценный кластер, но этот вариант будет стоить денег.
2. Скачать виртуальную машину (мануал №1 или мануал №2). В этом случае минусом будет, что все сервера кластера крутятся на одной машине.
Перейдем к способам болезненным. Hadoop первой версии в Windows потребует установки Cygwin. Плюсом здесь будет отличная интеграция со средами разработки (IntellijIDEA и Eclipse). Подробнее в этом замечательном мануале.
Начиная со второй версии, Hadoop поддерживает и серверные редакции Windows. Однако я бы не советовал пытаться использовать Hadoop и Windows не только в production’e, но и вообще где-то за пределами компьютера разработчика, хотя для этого и существуют специальные дистрибутивы. Windows 7 и 8 в настоящий момент вендоры не поддерживают, однако люди, которые любят вызов, могут попробовать это сделать руками.
Отмечу еще, что для фанатов Spring существует фреймворк Spring for Apache Hadoop.
Мы пойдем путем простым и установим Hadoop на виртуальную машину. Для начала скачаем дистрибутив CDH-5.1 для виртуальной машины (VMWare или VirtualBox). Размер дистрибутива порядка 3,5 гб. Cкачали, распаковали, загрузили в VM и на этом все. У нас все есть. Самое время написать всеми любимый WordCount!
Конкретный пример
Нам понадобится сэмпл данных. Я предлагаю скачать любой словарь для bruteforce’а паролей. Мой файл будет называться john.txt.
Теперь открываем Eclipse, и у нас уже есть пресозданный проект training. Проект уже содержитя все необходимые библиотеки для разработки. Давайте выкинем весь заботливо положенный ребятами из Clouder код и скопипастим следующее:
Получим примерно такой результат:
Нажимаем Apply, а затем Run. Работа успешно выполнится:
А где же результаты? Для этого обновляем проект в Eclipse (кнопкой F5):
В папке output можно увидеть два файла: _SUCCESS, который говорит, что работа была выполнена успешно, и part-00000 непосредственно с результатами.
Этот код, разумеется, можно дебажить и т. п. Завершим же разговор обзором unit-тестов. Собственно, пока для написания unit-тестов в Hadoop есть только фреймворк MRUnit (https://mrunit.apache.org/), за Hadoop он опаздывает: сейчас поддерживаются версии вплоть до 2.3.0, хотя последняя стабильная версия Hadoop — 2.5.0
Блиц-обзор экосистемы: Hive, Pig, Oozie, Sqoop, Flume
В двух словах и обо всем.
Hive & Pig. В большинстве случаев писать Map/Reduce job’ы на чистой Java — слишком трудоемкое и неподъемное занятие, имеющее смысл, как правило, лишь чтобы вытащить всю возможную производительность. Hive и Pig — два инструмента на этот случай. Hive любят в Facebook, Pig любят Yahoo. У Hive — SQL-подобный синтаксис (сходства и отличия с SQL-92). В лагерь Big Data перешло много людей с опытом в бизнес-анализе, а также DBA — для них Hive часто инструмент выбора. Pig фокусируется на ETL.
Oozie — workflow-движок для jobs. Позволяет компоновать jobs на разных платформах: Java, Hive, Pig и т. д.
Наконец, фреймворки, обеспечивающие непосредственно ввод данных в систему. Совсем коротко. Sqoop — интеграция со структурированными данными (РСУБД), Flume — с неструктурированными.
Обзор литературы и видеокурсов
Литературы по Hadoop пока не так уж много. Что касается второй версии, мне попадалась только одна книга, которая концентрировалась бы именно на ней — Hadoop 2 Essentials: An End-to-End Approach. К сожалению, книгу никак не получить в электронном формате, и ознакомиться с ней не получилось.
Я не рассматриваю литературу по отдельным компонентам экосистемы — Hive, Pig, Sqoop — потому что она несколько устарела, а главное, такие книги вряд ли кто-то будет читать от корки до корки, скорее, они будут использоваться как reference guide. Да и то всегда можно обойдись документацией.
Hadoop: The Definitive Guide — книга в топе Амазона и имеет много позитивных отзывов. Материал устаревший: 2012 года и описывает Hadoop 1. В плюс идет много положительных ревью и достаточно широкое покрытие всей экосистемы.
Lublinskiy B. Professional Hadoop Solution — книга, из которой взято много материала для этой статьи. Несколько сложновата, однако очень много реальных практических примеров —внимания уделено конкретным нюансам построения решений. Куда приятнее, чем просто читать описание фич продукта.
Sammer E. Hadoop Operations — около половины книги отведено описанию конфигурации Hadoop. Учитывая, что книга 2012 г., устареет очень скоро. Предназначена она в первую очередь, конечно же, для devOps. Но я придерживаюсь мнения, что невозможно понять и прочувствовать систему, если ее только разрабатывать и не эксплуатировать. Мне книга показалось полезной за счет того, что разобраны стандартные проблемы бэкапа, мониторинга и бенчмаркинга кластера.
Parsian M. «Data Algorithms: Recipes for Scaling up with Hadoop and Spark» — основной упор идет на дизайн Map-Reduce-приложений. Сильный уклон в научную сторону. Полезно для всестороннего и глубокого понимания и применения MapReduce.
Owens J. Hadoop Real World Solutions Cookbook — как и многие другие книги издательства Packt со словом “Cookbook” в заголовке, представляет собой техническую документацию, которую нарезали на вопросы и ответы. Это тоже не так просто. Попробуйте сами. Стоит прочитать для широкого обзора, ну, и использовать как справочник.
Стоит обратить внимание и на два видеокурса от O’Reilly.
Learning Hadoop — 8 часов. Показался слишком поверхностным. Но для меня некую ценность представили доп. материалы, потому что хочется поиграть с Hadoop, но нужны какие-то живые данные. И вот он — замечательный источник данных.
Building Hadoop Clusters — 2,5 часа. Как понятно из заголовка, здесь упор на построение кластеров на Амазоне. Мне курс очень понравился — коротко и ясно.
Надеюсь, что мой скромный вклад поможет тем, кто только начинает освоение Hadoop.
Hadoop
Apache Hadoop — это пакет утилит, библиотек и фреймворков, его используют для построения систем, которые работают с Big Data. Он хранит и обрабатывает данные для выгрузки в другие сервисы. У Hadoop открытый исходный код, написанный на языке Java. Это значит, что пользователи могут работать с ним и модифицировать его бесплатно.
Hadoop разделен на кластеры — группу серверов (узлов), которые используют как единый ресурс. Так данные удобнее и быстрее собирать и обрабатывать. Деление позволяет выполнять множество элементарных заданий на разных серверах кластера и выдавать конечный результат. Это нужно в первую очередь для перегруженных сайтов, например Facebook.
Внутри Hadoop существует несколько проектов, которые превратились в отдельные стартапы: Cloudera, MapR и Hortonworks. Эти проекты — дистрибутивы или установочный пакет программы, которые обрабатывают большие данные.
Архитектура Hadoop

Основные компоненты
Hadoop разделен на четыре модуля: такое деление позволяет эффективно справляться с задачами для анализа больших данных.
Hadoop Common — набор библиотек, сценариев и утилит для создания инфраструктуры, аналог командной строки.
Hadoop HDFS (Hadoop Distributed File System) — иерархическая система хранения файлов большого размера с возможностью потокового доступа. Это значит, что HDFS позволяет легко находить и дублировать данные.
HDFS состоит из NameNode и DataNode — управляющего узла и сервера данных. NameNode отвечает за открытие и закрытие файлов и управляет доступом к каталогам и блокам файлов. DataNode — это стандартный сервер, на котором хранятся данные. Он отвечает за запись и чтение данных и выполняет команды NameNode. Отдельный компонент — это client (пользователь), которому предоставляют доступ к файловой системе.
MapReduce — это модель программирования, которая впервые была использована Google для индексации своих поисковых операций. MapReduce построен по принципу «мастер–подчиненные». Главный в системе — сервер JobTracker, раздающий задания подчиненным узлам кластера и контролирующий их выполнение. Функция Map группирует, сортирует и фильтрует несколько наборов данных. Reduce агрегирует данные для получения желаемого результата.
YARN решает, что должно происходить в каждом узле данных. Центральный узел, который управляет всеми запросами на обработку, называется диспетчером ресурсов. Менеджер ресурсов взаимодействует с менеджерами узлов: каждый подчиненный узел данных имеет свой собственный диспетчер узлов для выполнения задач.
Дополнительные компоненты
Hive: хранилище данных
Система хранения данных, которая помогает запрашивать большие наборы данных в HDFS. До Hive разработчики сталкивались с проблемой создания сложных заданий MapReduce для запроса данных Hadoop. Hive использует HQL (язык запросов Hive), который напоминает синтаксис SQL.
Pig: сценарий преобразований данных
Pig преобразовывает входные данные, чтобы получить выходные данные. Pig полезен на этапе подготовки данных, поскольку он может легко выполнять сложные запросы и хорошо работает с различными форматами данных.
Flume: прием больших данных
Flume — это инструмент для приема больших данных, который действует как курьерская служба между несколькими источниками данных и HDFS. Он собирает, объединяет и отправляет огромные объемы потоковых данных (например файлов журналов, событий, созданных десктопными версиями социальных сетей) в HDFS.
Zookeeper: координатор
Zookeeper это сервис-координатор и администратор Hadoop, который распределяет информацию на разные сервера.
Data Scientist с нуля
Получите востребованные IT-навыки за один год и станьте перспективным профессионалом. Мы поможем в трудоустройстве. Дополнительная скидка 5% по промокоду BLOG.
Data Lake – от теории к практике. Методы интеграции данных Hadoop и корпоративного DWH
В этой статье я хочу рассказать про важную задачу, о которой нужно думать и нужно уметь решать, если в аналитической платформе для работы с данными появляется такой важный компонент как Hadoop — задача интеграции данных Hadoop и данных корпоративного DWH. В Data Lake в Тинькофф Банке мы научились эффективно решать эту задачу и дальше в статье я расскажу, как мы это сделали.

Данная статья является продолжением цикла статей про Data Lake в Тинькофф Банке (предыдущая статья Data Lake – от теории к практике. Сказ про то, как мы строим ETL на Hadoop).
Задача
Лирическое отступление. Выше на рисунке изображено живописное озера, а точнее система озер – одно поменьше, другое побольше. То, что поменьше, красивое такое, облагороженное, с яхтами – это корпоративное DWH. А то, что виднеется на горизонте и не помещается на картинке в силу своих размеров – это Hadoop. Лирическое отступление окончено, к делу.
Задача у нас была достаточно тривиальная с точки зрения требований, и нетривиальная с точки зрения выбора технологии и реализации. Нам надо было прорыть канал между этими двумя озерами, наладить простой и эффективный способ публикации данных из Hadoop в DWH и обратно в рамках регламентных процессов, проистекающих в Data Lake.
Выбор технологии
Далее расскажу про преимущества и недостатки каждого из них.
Sqoop
Sqoop — это средство, предназначенное для передачи данных между кластерами Hadoop и реляционными базами данных. С его помощью можно импортировать данные из системы управления реляционной базой данных (реляционной СУБД), например, SQL Server, MySQL или Oracle, в распределенную файловую систему Hadoop (HDFS), преобразовать данные в системе Hadoop с использованием MapReduce или Hive, а затем экспортировать данные обратно в реляционную СУБД.
Т.к. в задаче изначально не предполагалась трансформация, то вроде бы Sqoop идеально подходит для решения поставленной задачи. Получается, что как только появляется потребность публикации таблицы (или в Hadoop, или в Greenplum), необходимо написать задание (job) на Sqoop и это задание научиться вызывать на одном из планировщиков (SAS или Informatica), в зависимости от регламента.
Всё хорошо, но Sqoop работает с Greenplum через JDBC. Мы столкнулись с крайне низкой производительностью. Тестовая таблица в 30 Gb выгружалась в Greenplum около 1 часа. Результат крайне неудовлетворительный. От Sqoop отказались. Хотя в целом, это очень удобный инструмент для того что бы, например, выгрузить разово в Hadoop, данные какой-либо не очень большой таблицы из реляционной БД. Но, для того что бы строить регламентные процессы на Sqoop, нужно четко понимать требования к производительности работы этих процессов и исходя из этого принимать решение.
Informatica Big Data Edition
Informatica Big Data Edition мы используем как ELT движок обработки данных в Hadoop. Т.е. как раз с помощью Informatica BDE мы строим в Hadoop те витрины, которые нужно опубликовать в Greenplum, где они станут доступны другим прикладным системам банка. Вроде как логично, после того как ELT процессы отработали на кластере Hadoop, построили витрину данных, сделать push этой витрины в Greenplum. Для работы с СУБД Greenplum в Informatica BDE есть PWX for Greenplum, который может работать как в режиме Native, так и в режиме Hive. Т.е., как только появляется потребность публикации таблицы из Hadoop в Greenplum, необходимо написать задание (mapping) на Informatica BDE и это задание вызвать на планировщике Informatica.
Всё хорошо, но есть нюанс. PWX for Greenplum в режиме Native работает как классический ETL, т.е. вычитывает из Hive данные на ETL сервер и уже на ETL сервере поднимает сессию gpload и грузит данные в Greenplum. Получается, что весь поток данных упирается в ETL-сервер.
Далее провели эксперименты в режиме Hive. PWX for Greenplum в режиме Hive работает без участия ETL сервера, ETL сервер только управляет процессом, вся работа с данными происходит на стороне кластера Hadoop (компоненты Informatica BDE устанавливаются так же и на кластер Hadoop). В этом случае сессии gpload поднимаются на узлах кластера Hadoop и грузят данные в Greenplum. Здесь мы не получаем узкое место в виде ETL сервера и производительность работы такого подхода получилась достаточно хорошей — тестовая таблица в 30 Gb выгружалась в Greenplum около 15 минут. Но PWX for Greenplum в режиме Hive работал, на момент проведения исследований, нестабильно. И есть ещё один важный момент. Если требуется сделать обратную публикацию данных (из Greenplum в Hadoop) PWX for Greenplum работает через ODBC.
Для решения задачи было принято решение не использовать Informatica BDE.
SAS Data Integration Studio
SAS Data Integration Studio мы используем как ELT движок обработки данных в Greenplum. Здесь получается другая картина. Informatica BDE строит необходимую витрину в Hadoop, далее SAS DIS делает pull этой витрины в Greenplum. Или иначе, SAS DIS строит какую-либо витрину в Greenplum, далее делает push этой витрины в Hadoop. Вроде бы красиво. Для работы с Hadoop в SAS DIS есть специальные компонент SAS Access Interface to Hadoop. Проводя параллель с PWX for Greenplum, у SAS Access Interface to Hadoop нет режима работы Hive и поэтому все данные польются через ETL сервер. Получили неудовлетворительную производительность работы процессов.
gphdfs
gphdfs – утилита, входящая в состав СУБД Greenplum, позволяющая организовать параллельный транспорт данных между сегмент серверами Greenplum и узлами с данными Hadoop. Провели эксперименты с публикацией данных и из Hadoop в Greenplum, и обратно – производительность работы процессов просто поразила. Тестовая таблица в 30 Gb выгружалась в Greenplum около 2 минут.
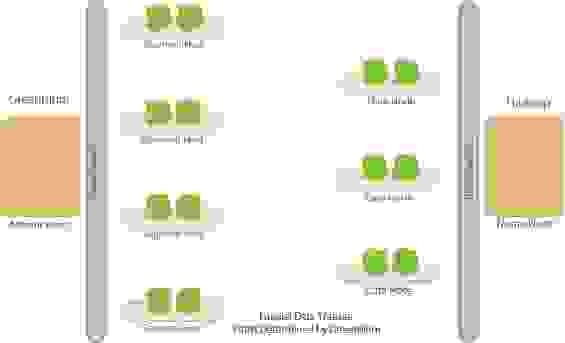
Анализ полученных результатов
Для наглядности в таблице ниже приведены результаты исследований.
Вывод получился двусмысленный — с наименьшими проблемами в производительности работы процессов, мы получаем утилиту, которую совершенно неприемлемо использовать в разработке ETL процессов как есть. Мы задумались… ELT платформа SAS Data Integration Studio позволяет разрабатывать на ней свои компоненты (трансформы) и мы решили, для того что бы снизить трудоемкость разработки ETL процессов и снизить сложность интеграции в регламентные процессы, разработать два трансформа, которые облегчат работу с gphdfs без потери производительности работы целевых процессов. Далее расскажу о деталях реализации.
Реализация трансформов
У этих двух трансформов достаточно простая задача, выполнить последовательно набор операций вокруг Hive и gphdfs.
Пример (дизайн) трансформа для публикации данных из Hadoop в Greenplum.
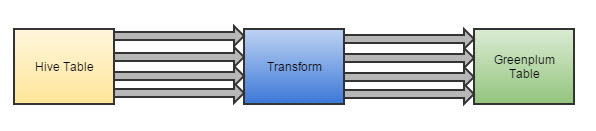
Разработчику остается добавить этот трансформ в job (задание) и указать названия входной и выходной таблиц.
Разработка такого процесса занимает около 15 минут.

По аналогии был реализован трансформ для публикации данных из Greenplum в Hadoop.
ВАЖНО. Ещё один из бенефитов который мы получили решив эту задачу, мы потенциально готовы организовывать процесс offload-а данных из корпоративного DWH в более дешевый Hadoop.
С чего начать внедрение Hadoop в компании

Алексей Еремихин ( alexxz )
Я хочу навести порядок в головах, чтобы люди поняли, что такое Hadoop, и что такое продукты вокруг Hadoop, а также для чего не только Hadoop, но и продукты вокруг него можно использовать на примерах. Именно поэтому тема — «С чего начать внедрение Hadoop в компании?»
Структура доклада следующая. Я расскажу:
Хранение данных. На самом деле, никому не нужно хранить данные, всем нужно их читать, вопрос только — сколько времени вам потребуется для того, чтобы прочитать эти данные, если они были записаны год-два назад. Задача чтения архивов данных. В следующих слайдах буду рассказывать про эти задачи по очереди.
Первая задача — хранение архивов. Данные нужно хранить долго, чтобы уметь их читать. Нужно хранить год, два, три. Нужно предполагать, что за год, два, три откажет железо (может отказать диск, сервер), а данные нельзя потерять.
Объемы данных растут. Вот, по примеру группы BI в компании Badoo я знаю, что у нас данные растут каждый год в два раза. Меня эта цифра пугает просто до ужаса. Я знаю, что через год у нас будет в два раза больше данных. Соответственно, хранилище для этих данных нужно масштабируемое, и нужно предполагать, что оно будет расти. И в качестве объекта, содержащего единицу информации, предполагается файл. Можно использовать и другие способы, но файл — это универсальный способ хранения, обработки и передачи информации, присутствует почти во всех операционных системах. Именно поэтому файл.
На картинке архив министерства обороны. Самое главное отличие их архивов от тех архивов, которые нам нужны, — это то, что их архивы читают единицы, а мы должны читать архивы массово, данные должны читать.
Что хочется получить от читалки архивов? Чтобы она позволяла унифицировано читать разные логи, потому что логи могли собираться в разное время, разными системами и исторические данные менять, как отправил, долго и сложно, альтеры какие-то делать… Т.к. объемы данных большие, нужно предполагать, что данные нужно читать параллельно. Если вы, например, 100 Мб зипа читаете, раззиповываете и данные из них вытаскиваете, то у вас это занимает несколько секунд, а если вам нужно раззиповать несколько Тбайт, то здесь вам придется параллелиться. Либо вы сами будете параллелиться, либо среда это будет делать за вас. И если ваша среда позволяет вам параллелиться — это здорово.
SQL доступ. Для меня язык SQL — самый универсальный язык доступа к данным и решения различных задач с данными. Важно понимать, что SQL — это не только таблицы, это в целом structure query language и все, что можно описать в виде таблиц или чего-то похожего на таблицу, можно описывать запросы к этим объектам на языке SQL. Это не что-то новое, так думают многие.
Задача чтения архивов — это задача распараллелиться, прочитать быстро и уметь быстро обработать. Что значит быстро обработать?
Например, собрать быстро какую-то статистику (сколько данных было), отфильтровать какого-то юзера, какую-то сессию с данными, просто найти нужный кусок в большом архиве, сделать из него маленькую выдержку… Как отдельная подзадача — число уникальных событий, когда к вам приходят 10 млн пользователей с 10-ти млн уникальных айпишников — это тоже нужно уметь делать, и было бы здорово, если бы система это могла делать, т.е. это еще одна задача — именно получение статистики, когда из большого количества данных получается немного таких значимых данных.
Отдельная задача — разбивать по параметрам. Как правило, нужно знать из каких городов события пришли, из каких стран события пришли, все зависит от системы, которую вы проектируете.
Четвертая задача — это подготовка данных. Она более хитрая, тоже связана с обработкой и чтением данных, но главное отличие от предыдущего пункта — если там я предлагал из Тбайта данных доставать Кбайты данных, то здесь я предлагаю из Тбайтов данных доставать Мбайты или Гбайты данных. Т.е. вы храните очень много данных и вам нужно предоставить какую-то систему, которая на выдержках из этих данных может работать. Как пример, решение задач рекомендаций. Вам нужно посмотреть, кто что и с чем покупал, и выдать рекомендации к какому продукту нужно рекомендовать другие продукты. Т.е. у вас есть логи, кто что покупал, но эти самые логи еще бесполезны, потому что нужно сделать связки продуктов. Получается, что для того, чтобы связать продукты между собой, их нужно связать непосредственно через логи покупок. Задача сводится к тому, что нужно взять очень много данных, которые есть (как правило, там еще произойдет декартово произведение этих данных на какую-нибудь ерунду — данных станет еще больше), а потом вы сделаете какую-то выдержку, которую положите в MySQL или PostgreSQL — вообще, в любое хранилище, которое может хорошо обрабатывать не очень большие объемы данных, и будете с ними работать.
Пункт про ETL — это штука из мира BI — Extract, Transform, Load. По большому счету, это просто перекладывание данных, когда вы данные берете из одного места, приводите к нужному виду и кладете в другую базу данных. Как правило, это сбор с нескольких баз данных в одну, изменение форматов, каких-то соглашений. Опять под эту задачу очень хорошо ложиться SQL, но не как язык, который вернет нам немного данных, а как язык, в котором можно create table as select, и там будет уже много данных, т.е. вы создадите себе таблицу.
Собственно, вот четыре задачи: первая — это чтение данных, и три задачи про обработку данных. Эти самые задачи я и предлагаю решить с помощью Hadoop.
Hadoop, наверное, не единственное предложение на рынке, которое позволяет это делать, но из open source, бесплатного и решающего все задачи, наверное единственный.
Конференция называется highload, а Hadoop — из мира big data. Как highload соотносится с big data? По большому счету, когда highload начинает писать логи, то для обработки этих логов уже нужен big data. Вообще, big data — это очень широкая область с машинным обучением, с какими-то семантическими анализами, с кучей всего. По этому поводу проводятся отдельные конференции… И Hadoop –непременный атрибут чуть ли не каждого доклада в области big data.
Проект Hadoop стартовал в 2007-ом году как open source открытая реализация идеи, предложенной Google’ом еще в 2004-ом году, названной MapReduce. MapReduce — это способ организации алгоритмов, когда вы определяете две небольшие процедурки MapReduce для обработки данных, и эти процедурки, по большому счету, запускаются за вас, т.е. это такие callback’и, которые запускаются в куче мест, распараллеленные и обрабатывают большое количество данных. Это способ организации алгоритмов, потому что сам MapReduce — это не алгоритм сортировки, поиска или еще чего-либо, это способ, паттерн проектирования алгоритмов.
Как открытая реализация идеи предложенной в 2004-ом году Google’ом в 2007-ом году появляется Hadoop как MapReduce, и проект развивается-развивается-развивается, обзаводится кучей проектов вокруг себя, сильно и слабо связанных, и в частности, в ядро Hadoop попадает, для Hadoop проектируется и создается распределенная файловая система HDFS.
В этот момент Hadoop начинает подходить для решения задач хранения данных.
HDFS — это распределенная файловая система, которая позволяет хранить очень-очень много данных, но не очень-очень много файлов. Предполагается, что в ней будут лежать большие файлики, и данные будут писаться туда один раз, т.е. перезаписи данных не предусмотрено.
Вторая часть Hadoop изначально называлась MapReduce — обработка данных. Сейчас Hadoop вырос, буквально года полтора назад код, написанный для MapReduce, распался на две части — на YARN и MapReduce.
YARN — это Yet Another Resource Negotiator — это такая штука, которая отвечает за запуск задач на куче машин, управляет вычислительными ресурсами кластера и просто передает задачи на выполнение. Она не знает, какие задачи передает, а MapReduce — уже непосредственно задачи, которые запускаются.
Чуть подробнее про HDFS.
Просто файл — это кусок данных с именем. Это, наверное, самое точное определение файла, и в имени может быть все, что угодно. Если вы добавите слэши, например, в имя файла, вы получите директории.
При проектировании HDFS сразу подходили к идее того, что система должна быть отказоустойчивой, т.е. данные должны храниться на разных серверах, на разных дисках, система должна быть распределенной, чтоб в нее можно было легко добавлять, удалять новые сервера. Устройство очень простое, т.е. файл представляется в виде имени и его содержимого, содержимое разбивается на набор блоков (по умолчанию это 64 Мб, но можете указать свой), и данные получаются в виде списка блоков.
Далее, есть сервис NameNode, который просто помнит, из каких блоков состоит файл, про сами блоки не знает ничего, он просто помнит, что файл — это блоки А, B, C и D и знает, на каких хранилищах DataNode 1,2,3,4 эти самые блоки хранятся.
Как видите на картинке, каждый блок хранится в трех экземплярах — три желтеньких, три зелененьких, три фиолетовых. Это означает, что фактор репликации — 3 (три). Если коротко, то это означает, что можно потерять два любых сервера, и данные, все равно, еще будут доступны, и можно будет их восстановить и добавить еще копии файлов.
Те, кто работают в системе Linux, как правило, проблем в работе с Hadoop не испытывают, потому что команды для работы с файлами более-менее все те же самые. На слайде вы их видите. Есть специфичные, но тоже очень очевидные команды из серии «положить локальную файловую систему на удаленную файловую систему»; «забрать данные обратно»; setrep — это «установить фактор репликации» и text — это «сказать Hadoop то, что у меня файлики лежат в разных форматах зазипованные, раззипуй мне их, пожалуйста, и отдай просто в виде текста, я не хочу сам по расширению файла догадываться каким архиватором его раззиповывать». Это из командной строки.
Конечно же, при непосредственном внедрении, т.е. из командной строки работают разработчики и админы, когда работают с данными руками. Как правило, работа идет через API. Hadoop написан на Java, поэтому API джавовская, но есть классная штука, называется WebHDFS — это HTTP Rest API, обертки, по-моему, есть уже для всех языков.
Вторая часть, связанная с обработкой данных, это вторая, третья и четвертая задачи. Как я уже говорил, это Yet Another Resource Negotiator/MapReduce. Принцип строения такой же, как и HDFS — есть мастер нода, которая рулит всем подряд и есть ноды менеджеры — это демоны, запущенные на каждом из серверов, на которых вы ходите обрабатывать данные, и они просто знают сколько ресурсов осталось на данном сервере, и говорят «у меня еще есть ресурсы, может я тебе еще чего-нибудь запущу».
Для внедрения этого всего знать не надо, просто показываю, как устроено.
Здесь закончился центр Hadoop. Т.е. есть такая штука — Hadoop common называется — это распределенная файловая система и MapReduce framework. MapReduce framework предполагает, что вы взяли java и стали писать на java под этот фреймворк и оптимизировать свои задачи. Для тех, кто хочет от Hadoop что-нибудь еще, должны взять что-нибудь еще.
Одним из старых проектов, в то же время стабильных и хороших, является Hive.
Вообще, этот желтый слоник вокруг Hadoop все вьется-вьется-вьется различными способами. Hive в переводе с английского — это улей, поэтому так вот слоник мимикрировал в пчелку.
Идея Hive была в том, чтобы предоставить доступ к файлам, лежащим в HDFS, в виде SQL. Т.е. любой более-менее структурированный лог можно описать каким-то способом, можно сказать, что это json там лежит, можно сказать, что запятыми данные разделены, тогда получается commons, Comma Separated Values (CSV), можно сказать о том, что там пробелом разделены какие-то способы структурирования данных и задать имена для этих частей данных.
SQL доступ к данным осуществляет в первую очередь Hive. Другие проекты тоже есть, но они не единственные. Как я уже сказал, SLQ удобен и с точки зрения вытащить пример данных, и с точки зрения собрать какую-то статистику, потому что у вас есть и count и max, различные агрегирующие функции, есть группировка, а также SQL в виде create table as select подходит для преобразования данных.
Как пример, стянутый с туториалов Hive, как распарсить apache access log:
На самом деле, формат, который лежит в логе apache access log называется Combined Log Format, и самый простой способ для Hive его описать в виде регулярки. Вы видите на слайде внизу регулярочка есть. Просто регуляркой описали, что у вас лежит в строке, и сказали, что в первой части лежит host, вторая — это identity, user, time, что записали в логи, что описали в регулярке, то и видно.
Регулярка — это, наверное, самый неэффективный способ описывания данных, потому что регулярное выражение будет применяться к каждой строке и это достаточно накладная операция, но в то же время один из самых гибких способов для доступа, для описания данных. Собственно, пятая строка снизу описывает, что именно регуляркой будет парситься.
В конце видно, что это RegexSerDe, SerDe — это сериалайзер-десериалайзер — это java класс, который для Hive описывает, как распарсить строку в данные, и как из данных снова сделать строку. По большому счету, для доступа к данным вы создаете таблицу виртуальную, говорите, что она лежит по какому-то пути в HDFS, и вы можете делать селект из этой таблицы и получать свою статистику.
Я рассказал сейчас про Hadoop common и про Hive — это два продукта. А, вообще, вокруг Hadoop много различных приложений и систем:
Можно попробовать разбить их по категориям управления данными, т.е. это файлы, ресурсы — то, что распределяет вычислительные ресурсы, фреймворк — это то, что организовывает вам вычисления, то что запускает ваши маперы, редьюсы или другие приложения, и, собственно, приложения — это, когда вы уже как пользователь код не пишете, пишете хотя бы SQL для обработки данных.
Желтеньким отмечено то, про что я вам рассказал, — HDFS, YARN, MapReduce, Streaming (чуть позже про него расскажу). Все остальное зелененькое — это отдельно стоящие продукты. Какие-то продукты предоставляют только фреймворк, какие-то предоставляют управление ресурсами, какие-то являются полноценными, т.е. они просто занимаются обработкой данных. Например, Hbase — это key-value хранилище, которое свои данные, свои файлики может хранить в HDFS. Файловых систем тоже куча, из забавного можно сказать, что не обязательно хранить данные в HDFS, их можно хранить просто на диске, просто среда для организаций вычислений.
Экосистема. Когда-то в Hadoop кто-то ввел, использовал слово «экосистема», и так называли все продукты, имеющие отношение к Hadoop. Я нашел список, где перечислены 150 различных продуктов и систем, имеющих отношение к Hadoop, среди них и система сбора данных, и машинное обучение, и SQL, и NoSQL.
Ищите подходящие продукты под ваши задачи, я не знаю, какие у вас задачи, я рассказал самые базовые, которые есть. Кто-то мне говорил, что есть другая классификация, там 300 продуктов существует вокруг Hadoop. Но, как я уже сказал, Hadoop — это такое слово, которое часто описывает всю экосистему, все продукты, все это семейство.
Теперь немножко о Hadoop в Badoo.
Зачем вам эти цифры могут оказаться полезными? Цифры могут оказаться полезными, с той точки зрения, что Hadoop масштабируется достаточно линейно. Т.е. если вы предполагаете объемы данных в два раза больше, вы просто умножаете цифры на два. Если вы планируете объемы данных в два раза меньше, делите эти цифры на два.
Естественно, все это имеет отношение к задачам, потому что в зависимости от задач, которые вы решаете, вы будете упираться в различные вещи. Кто-то будет упираться в сеть, кто-то будет упираться в процессы, кто-то будет упираться в производительность диска. Ничего обещать никто не сможет. Просто прикидывать и смотреть.
Кластер, на самом деле, небольшой — 15 серверов. В общем, все написано.
Почему 2 сервера подготовки данных? Потому что Badoo располагается в двух датацентрах — один находится в Праге, другой — в Майами. В каждом датацентре мы подготавливаем данные — это значит, что собираем со всего датацентра то, что мы хотим положить в Hadoop, зазиповываем и уже между датацентрами передаем в заархивированном виде.
Объемы данных, которые мы собираем:
В принципе, по одному серверу в каждом датацентре стоит, получается, что приходит 1 Гбит трафика, т.е. по большому счету, скоро начнем упираться в сеть, будем, наверное, в каждом датацентре ставить еще по одному серверу.
Что еще интересного — вот файлов и блоков похожее количество. Файлики мы специально делаем не очень большими, потому что большие файлики в зазипованном виде читаются очень плохо.
Средний фактор репликации — 2.75, а не 3, потому что у нас есть большой кусок данных, который мы реально не очень боимся потерять, но просто приятно его иметь и тратить на хранение 20 Тбайт. Вам нужно сохранить 20 Тбайт, у вас фактор репликации 3, значит, вы должны подготовить 60 Тбайт дисков. Если вы решаете поставить фактор репликации 2, у вас тут же появляется лишние 20 Тбайт дисков — это вкусно. Данные обязательно сжаты, потому что у нас самая используемая, самая проблемная вещь — это объемы данных.
Это была первая задача. Т.е. этот слайд — это про хранение данных, про то, как устроены распределенные файловые системы — это первая задача про хранение данных.
Вторая, третья и четвертая задачи — это про обработку данных. Инструменты, которые используем — Hive, Spark и еще используем Streaming. Если нужно просто подготовить какие-то данные, например, раз в день собрать суточные счетчики пользователей или еще что-то, используем Hive. Для ручного доступа, ручного анализа, Hive тоже подходит. Как в любой базе данных написал SQL, получил результат, можете сразу какие-то визуализаторы прикручивать, потому что, по-моему, у него есть JDBC — взяли и прикрутили.
Есть у нас в компании такая система старая, она еще организована на RRD, но суть в том, что хранит т.н. timeseries. Это когда вы храните какое-то значение во времени, и чем ближе к сегодня, тем более детальные данные вы хотите знать, т.е. данные за сегодня вы храните в разбивке по минуте, а данные за три года назад вы храните в разбивке хотя бы по дням. В целом эта штука называется timeseries. Чтобы кормить timeseries хранилище нужно собирать данные, собирать какое-то значение за последний день или за последний час.
У нас два основных окна, в принципе, мы с разными окнами работаем. Для такого онлайн процессинга, его часто называют realtime. Realtime в мире Hadoop — это значит, что вы что-то сделали в течение пяти минут. Это совсем не realtime.
Мы используем Spark. Spark когда-то появился как еще одна реализация MapReduce, потому что Hadoop был отчасти монополистом на рынке и хотели создать ему альтернативу. Сделали Spark, и он отлично вписался в экосистему Hadoop, вошел в семейство. Там SQL доступ есть, там и Streaming есть, там и машинное обучение в Spark’e есть. Это еще один комбайн, который вокруг себя всякой ерундой обрастает. Streaming — это такая маленькая штука, которая входит в Hadoop common и позволяет писать MapReduce задачи, вообще, на любом языке. Вот, хотите на баше, напишите на баше, организация очень простая — вы передаете ему две утилиты, которые на вход принимают то, что было прочитано из HDFS, а на выходе то, что вы хотите получить.
Про организацию MapReduce, я надеюсь, либо вы знаете, либо вы выучите, потому что про MapReduce мне потребуется примерно еще час рассказать, как он устроен.
Форматы, которые мы используем, — json, tab separated. Два основных формата.
Tab separated используем, когда мы точно знаем, какие столбцы и в каких логах мы хотим хранить, и никаких сложных данных в них не предвидится.
Json нужен на тот случай, когда мы хотим хранить абсолютно все в одном логе, но данные нужно как-то структурировать, потому что в зависимости от типа записи, вы хотите видеть разные столбцы, разные типы.
Слайд «Просто советы» — это где-то грабли, на которые мы наступили, где-то то, что нам очень сильно помогло в процессе внедрения Hadoop, и что-то, что может быть вам полезно, когда вы придете к себе в компанию и вдруг начнете внедрять Hadoop. Просто полезный слайд, который вам даст кучу подсказок, как хранить данные.
Gzip — он жмет средне-быстро, и, вообще, универсальный формат, используется много где. Если bzip2 с ним сравнить, вот bzip2 требует в 10 раз больше процессора, а коэффициент сжатия у него процентов на 10 всего, т.е. на 10% лучше. Очень тяжелая штука, но главное отличие между gzip и bzip — то, что если вы взяли 1 Тбайт, зазиповали его, чтобы его прочитать и обработать, вы на самом деле возьмете его с самого начала этого зазипованного Тбайта и будете его читать. Вы не сможете запустить второй поток, который читает середину. Если взять формат bzip2, его можно читать с середины, и Hadoop, увидев большой файлик, попытается его разбить и читать в несколько потоков.
lzo — эта штука, которая практически не ест процессор, но жмет хуже, чем bzip, есть еще какой-то атрибут у lzo, что он бывает индексит и тогда его тоже можно разбивать как bzip.
Чего не надо делать. Не надо запускать Hadoop на слабом железе — это первые три пункта. Его можно запустить, но вы при этом получите кучу ограничений, т.е. возьмете и запустите все на одном сервере, вы не получите ни избыточности, ни нормальной распараллеливаемости, ничего. Если у вас маленький проект, и вы хотите его поставить, Hadoop не нужен для одного маленького проекта — это иллюзия.
На одном сервере можно поставить все, но тогда вы получите, например, девел или какое-то тестовое окружение. Меньше 1 Гб памяти — да демоны Hadoop просто при старте жрут достаточно прилично, поэтому если у вас есть 1 Гб памяти на сервере — да, вы сможете запустить Hadoop, но какие-то тяжелые вычисления уже, в принципе, не сможете сделать. Если у вас есть сервера с кучей дисков и слабыми процессорами, вы можете организовать хранилище. Но это будет именно хранилище, а не читалище. Т.е. вы по большому счету данные оттуда сможете читать, но эти сервера не будут участвовать в обработке данных.
Маленький проект — невыгодно. Опять же, если у вас маленький проект, то сама идея поставить четыре сервера под Hadoop кластер может показаться кому-то очень странной. В то же время, если в вашей компании много маленьких проектов, вы все данные этих проектов можете объединить в рамках одного Hadoop кластера.
Из того, что надо делать, если ваша компания существует на рынке лет 5. Как правило, остаются какие-то сервера, которые просто стоят в стойках, греют воздух и их надо утилизировать, а утилизировать — это, как правило, еще деньги требуются, бизнес их не утилизирует, зато вы можете утилизировать их ресурсы, добавив в Hadoop. Hadoop достаточно хорошо принимает слабое железо в кластер, выводит из кластера, так что можете продлить жизнь старым серверам. Старые сервера часто отказывают, но как я уже объяснял, Hadoop это просто не важно, потому что Hadoop к этому готов. Hadoop проектировался для систем, где работают тысячи серверов, и поэтому отказ или одновременный простой одного-двух серверов — это абсолютная норма.
Больше всего, наверное, нас расстроило то, что в Hadoop нет разноса по датацентрам, чего бы нам очень хотелось, но, увы, нет, не стоит на это рассчитывать.
Три книжки по Hadoop, все три — на английском, возможно, есть переводы на русский, не знаю. Это реально книги, которые нужно читать вместо мануалов. Потому что мануалы не всегда хорошие, а книжки отвечают на гораздо больше вопросов.
Первая — «Hadoop Definitive Guide» — нужна всем, кто работает с Hadoop так или иначе. Снизу две книжки — «MapReduce Design Patterns» и «Hadoop Operations» — левая книжка для разработчиков, правая — для админов. Если вы занимаетесь и тем и другим, то читайте обе.
Контакты
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля «Российские интернет-технологии», в который входит восемь конференций, включая HighLoad++ Junior. Подключайтесь! Мы действительно поднимем цены сразу после Нового года.



