Производительность железа, измеряемая во флопсах: что это и с чем едят?
Авторизуйтесь
Производительность железа, измеряемая во флопсах: что это и с чем едят?
Новейшее поколение игровых консолей достигло отметки в десяток терафлопс. Но что именно означает эта величина?
Производительность, измеряемая во FLOPS — это количество операций с плавающей запятой, которое может выполнить устройство за одну секунду. Отсюда и название: FLoating-point Operations Per Second. Сравнивать вычислительную мощность по флопсам намного проще, чем по тактовой частоте или чему-либо ещё.

График роста производительности суперкомпьютеров
Современная техника имеет колоссальную мощность. Поэтому, что бы не использовать большое количество нолей, к флопсам добавляют приставки СИ: гигафлопсы, терафлопсы, петафлопсы.
Краткий список железа и его производительности:
Самым слабым компьютером можно назвать Z3. Его вычислительная мощность составляет 2 флопса. Да, верно — он осиливает всего 2 операции в секунду. Но это простительно, ведь Z3 — первая работоспособная программируемая вычислительная машина, собранная ещё в 1940 г.

Вычислительная машина Z3
Cамым мощным компьютером на момент 2020 года можно назвать Фугаку — японский суперкомпьютер. Его заявленная мощность составляет 0,54 эксафлопса (для 64-разрядных вычислений). Это 540 000 терафлопс.
Терафлопс
![]()

Терафлопс (TFLOPS) — величина, используемая для измерения производительности компьютеров, показывающая, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система. 1 терафлопс = 1 триллион операций в секунду = 1000 миллиардов операций в секунду. Обычно имеются в виду операции над плавающими числами размера 64 бита в формате IEEE 754.
TFLOPS = 10 12 FLOPS (= 10 3 GFLOPS)
При измерении производительности кластеров и суперкомпьютеров часто используется 2 варианта: пиковая производительность — теоретический предел производительности (выражаемый через операции с плавающий точкой) для данных процессоров и максимальная производительность, которую данный кластер или компьютер достигает при решении практических задач. В качестве эталонной задачи часто выступает задача решения системы СЛАУ методом LU-разложения. Для измерений на кластерах используется реализация HPL — High performance linpack.
Чтобы найти пиковую производительность ЭВМ R, терафлопс, нужно тактовую частоту F, МГц, умножить на число процессоров (процессорных ядер) n, домножить на количество инструкций с плавающей запятой на такт (4 для процессоров Core2 — 2 операции Float Multiple Add; 8 для процессоров с AVX) и поделить на 1000000:
Например, суперкомпьютер eServer Blue Gene Solution (на май 2008 года был самым производительным на планете), который работает в Ливерморской национальной лаборатории, штат Калифорния, США, обладает пиковой производительностью 596,4 терафлопс. Максимальная производительность — 478,2 терафлопс — составляет 80 % от пиковой. Производитель — американская корпорация IBM.
Эта суперЭВМ собрана на базе 212992 процессоров PowerPC 440, тактовая частота каждого из которых 700 МГц. Его производительность:
700 МГц × 212992 процессоров × 4·10 −6 = 596,4 трлн операций в секунду = 596,4 терафлопс.
В общем случае, соотношение максимальной и пиковой производительности варьируется от 60 % до 83 %, поэтому по указанной формуле можно вычислять лишь пиковую производительность суперЭВМ. Так, например, пиковая производительность компьютера на базе четырехъядерного процессора AMD Phenom 9500 sAM2+ с тактовой частотой 2,2 ГГц равна:
2200 МГц × 4 ядра × 4·10 −6 = 3,52 млрд операций в секунду = 0,0352 терафлопс.
Для четырехъядерного процессора Core 2 Quad Q6600:
2400 МГц × 4 ядра × 4·10 −6 = 3,84 млрд операций в секунду = 0,0384 терафлопс.
Кроме того, AMD представила вычислительную систему FireStream 9250, занимающую один разъем PCI, общая производительность которой превосходит терафлопс, но только на 32-х разрядных данных, тогда как для суперкомпьютеров принято считать производительность на 64-х разрядных данных.
На данный момент (июнь 2011) самый мощный суперкомпьютер K computer, занимает первую строчку в рейтинге суперкомпьютеров, его пиковая производительность составляет 11,280 петафлопс, а максимальная 10,510 петафлопс([1]).
Терафлопс – что это такое? – как измеряется TFLOP у компьютеров
Терафлопс – это важный показатель производительности видеокарты и процессора. Обычно, чем выше это число, тем выше производительность, но есть некоторые нюансы, которые следует учитывать. В этой статье есть все, что вам нужно знать при сравнении некоторых из самых мощных процессоров в мире.
Если вы хотите купить новую Microsoft Xbox X или даже просто видеокарту для ПК, скорее всего вы столкнётесь с довольно новым термином TFLOP (терафлопс).
Что такое TFLOP?
В отличие от гигагерца (ГГц), который измеряет тактовую частоту процессора, TFLOP является прямым измерением производительности компьютера.

В частности, терафлопс относится к способности процессора вычислять 1 триллион операций с плавающей запятой в секунду. Например, скажем что-нибудь с «6 TFLOP», то есть его процессор способен обрабатывать в среднем 6 триллионов операций с плавающей запятой в секунду.
Microsoft оценивает свой собственный процессор Xbox Series X в 12 TFLOP, то есть консоль способна выполнять 12 триллионов операций с плавающей запятой в секунду. Для сравнения: графический процессор AMD Radeon Pro в 16-дюймовом MacBook Pro от Apple имеет 4 TFLOP, а переработанный Mac Pro – 56 TFLOP.
TFLOP важен для игр?
Microsoft недавно раскрыла подробности о Xbox Series X, заявив, что ее графический процессор имеет производительность до 12 TFLOP. Это вдвое больше, чем 6 TFLOP на Xbox Series X и в 8 раз больше возможностей оригинального Xbox One. Microsoft описала это как настоящий скачок в обработке и графике.
Повышение вычислительной мощности крайне важно для игр, особенно когда новый Xbox будет использовать аппаратно-ускоренную трассировку DirectX Ray (с лучей трассировкой). Настройте у себя Variate Rate Shading (VRS), чтобы сделать сцены видеоигр более реалистичными.
Освещение сцены, чтобы показать, что свет поглощается, отражается или преломляется, требует графических и консольных возможностей, которые будут полагаться на его кремний 12-TFLOP, чтобы дать игрокам еще лучший опыт.
Реальная производительность зависит от таких факторов, как архитектура процессора, кадровые буферы, скорость ядра и другие важные характеристики.
Высокий TFLOP определяет быстродействие устройства, лучшую графику. Всего несколько лет назад потребительские устройства не могли даже посчитать уровень TFLOP, но сейчас многие устройства достигают уровня 6–11 TFLOP.
Исследователи, которые сравнивают спецификации, в настоящее время обсуждают суперкомпьютеры с более чем 100 PETAFLOP (1 PETAFLOP равен 1000 TFLOP). В настоящее время рекорд производительности, который ведется суперкомпьютером IBM в Национальной лаборатории Ок-Риджа, достигает 122,3 PETAFLOP.
FLOPS
| Производительность суперкомпьютеров | ||
|---|---|---|
| Название | год | FLOPS |
| флопс | 1941 | 10 0 |
| килофлопс | 1949 | 10 3 |
| мегафлопс | 1964 | 10 6 |
| гигафлопс | 1987 | 10 9 |
| терафлопс | 1997 | 10 12 |
| петафлопс | 2008 | 10 15 |
| эксафлопс | 10 18 | |
| зеттафлопс | − | 10 21 |
| йоттафлопс | − | 10 24 |
Поскольку современные компьютеры обладают высоким уровнем производительности, более распространены производные величины от FLOPS, образуемые путём использования кратных приставок системы СИ.
Содержание
Флопс как мера производительности
Как и большинство других показателей производительности, данная величина определяется путём запуска на испытуемом компьютере тестовой программы, которая решает задачу с известным количеством операций и подсчитывает время, за которое она была решена. Наиболее популярным тестом производительности на сегодняшний день является программа Linpack, используемая, в том числе, при составлении рейтинга суперкомпьютеров TOP500.
Одним из важнейших достоинств показателя флопс является то, что он до некоторых пределов может быть истолкован как абсолютная величина и вычислен теоретически, в то время как большинство других популярных мер являются относительными и позволяют оценить испытуемую систему лишь в сравнении с рядом других. Эта особенность даёт возможность использовать для оценки результаты работы различных алгоритмов, а также оценить производительность вычислительных систем, которые ещё не существуют или находятся в разработке.
Границы применимости
Несмотря на кажущуюся однозначность, в реальности флопс является достаточно плохой мерой производительности, поскольку неоднозначным является уже само его определение. Под «операцией с плавающей запятой» может скрываться масса разных понятий, не говоря уже о том, что существенную роль в данных вычислениях играет разрядность операндов, которая также нигде не оговаривается. Кроме того, величина флопс подвержена влиянию очень многих факторов, напрямую не связанных с производительностью вычислительного модуля, таких как: пропускная способность каналов связи с окружением процессора, производительность основной памяти и синхронность работы кэш-памяти разных уровней.
Всё это, в конечном итоге, приводит к тому, что результаты, полученные на одном и том же компьютере при помощи разных программ, могут существенным образом отличаться, более того, с каждым новым испытанием разные результаты можно получить при использовании одного алгоритма. Отчасти эта проблема решается соглашением об использовании единообразных тестовых программ (той же LINPACK) с усреднением результатов, но со временем возможности компьютеров «перерастают» рамки принятого теста и он начинает давать искусственно заниженные результаты, поскольку не задействует новейшие возможности вычислительных устройств. А к некоторым системам общепринятые тесты вообще не могут быть применены, в результате чего вопрос об их производительности остаётся открытым.
Так, например, 24 июня 2006 года общественности был представлен суперкомпьютер MDGrape-3, разработанный в японском исследовательском институте RIKEN (Йокогама), с рекордной теоретической производительностью в 1 Пфлопс. Однако данный компьютер не является компьютером общего назначения и приспособлен для решения узкого спектра конкретных задач, в то время как стандартный тест LINPACK на нём выполнить невозможно в силу особенностей его архитектуры.
Причины широкого распространения
Несмотря на большое число существенных недостатков, показатель флопс продолжает с успехом использоваться для оценки производительности, базируясь на результатах теста LINPACK. Причины такой популярности обусловлены, во-первых, тем, что флопс, как говорилось выше, является абсолютной величиной. А во-вторых, очень многие задачи инженерной и научной практики в конечном итоге сводятся к решению систем линейных алгебраических уравнений, а тест LINPACK как раз и базируется на измерении скорости решения таких систем. Кроме того, подавляющее большинство компьютеров (включая суперкомпьютеры) построены по классической архитектуре с использованием стандартных процессоров, что позволяет использовать общепринятые тесты с большой достоверностью.
Обзор производительности реальных систем
Из-за высокого разброса результатов теста LINPACK, приведены примерные величины, полученные путём усреднения показателей на основе информации из разных источников. Производительность игровых приставок и распределённых систем (имеющих узкую специализацию и не поддерживающих тест LINPACK) приведена в справочных целях в соответствии с числами, заявленными их разработчиками. Более точные результаты с указанием параметров конкретных систем можно получить, например, на сайте The Performance Database Server.
Суперкомпьютеры
Процессоры персональных компьютеров
Карманные компьютеры
Распределённые системы
Данные приведены по состоянию на 26 июля 2011 года
Игровые приставки
Указаны операции с плавающей точкой над 32-разрядными данными
GPU-процессоры
Теоретическая производительность (FMA; гигафлопсы):
| GPU | GFLOPS с точностью 32 бита | GFLOPS с точностью 64 бита | Источник |
|---|---|---|---|
| GeForce GTX 590 | 2×1253,4 = 2507.4 | 2x 156,7 = 313.4 | [33] |
| GeForce GTX 580 | 1581,1 | 197,6 | [33] |
| Radeon HD 7970 | 3789 | 947 | [34] |
| Radeon HD 6990 | 2×2550 = 5100 | 2x 637 = 1274 | [34] |
| Radeon HD 5970 (AIB vendors) | 2x 2320 = 4640 | 2x 464 = 928 | [34] |
Человек и калькулятор
Калькулятор не случайно попал в одну категорию вместе с человеком, поскольку хотя он и является электронным устройством, содержащим процессор, память и устройства ввода/вывода, режим его работы кардинально отличается от режима работы компьютера. Калькулятор выполняет одну операцию за другой с той скоростью, с какой их запрашивает человек-оператор. Время, проходящее между операциями, определяется возможностями человека и существенно превышает время, которое затрачивается непосредственно на вычисления. Можно сказать, что в среднем производительность обычного карманного калькулятора составляет 10 флопс.
Человек, пользуясь лишь ручкой и бумагой, выполняет операции с плавающей запятой очень медленно и часто с большой ошибкой. Говоря о производительности нашего вычислительного аппарата, придётся использовать такие единицы как миллифлопс и даже микрофлопс.
Как и зачем мерить FLOPSы
 Как известно, FLOPS – это единица измерения вычислительной мощности компьютеров в (
Как известно, FLOPS – это единица измерения вычислительной мощности компьютеров в (попугаях) операциях с плавающей точкой, которой часто пользуются, чтобы померить у кого больше. Особенно важно померяться FLOPS’ами в мире Top500 суперкомпьютеров, чтобы выяснить, кто же среди них самый-самый. Однако, предмет измерения должен иметь хоть какое-нибудь применение на практике, иначе какой смысл его замерять и сравнивать. Поэтому для выяснения возможностей супер- и просто компьютеров существуют чуть более приближенные к реальным вычислительным задачам бенчмарки, например, SPEC: SPECint и SPECfp. И, тем не менее, FLOPS активно используется в оценках производительности и публикуется в отчетах. Для его измерения давно уже использовали тест Linpack, а сейчас применяют открытый стандартный бенчмарк из LAPACK. Что эти измерения дают разработчикам высокопроизводительных и научных приложений? Можно ли легко оценить производительность реализации своего алгоритма в FLOPSaх? Будут ли измерения и сравнения корректными? Обо всем этом мы поговорим ниже.
Давайте сначала немного разберемся с терминами и определениями. Итак, FLOPS – это количество вычислительных операций или инструкций, выполняемых над операндами с плавающей точкой (FP) в секунду. Здесь используется слово «вычислительных», так как микропроцессор умеет выполнять и другие инструкции с такими операндами, например, загрузку из памяти. Такие операции не несут полезной вычислительной нагрузки и поэтому не учитываются.
Значение FLOPS, опубликованное для конкретной системы, – это характеристика прежде всего самого компьютера, а не программы. Ее можно получить двумя способами – теоретическим и практическим. Теоретически мы знаем сколько микропроцессоров в системе и сколько исполняемых устройств с плавающей точкой в каждом процессоре. Все они могут работать одновременно и начинать работу над следующей инструкцией в конвеере каждый цикл. Поэтому для подсчета теоретического максимума для данной системы нам нужно только перемножить все эти величины с частотой процессора – получим количество FP операций в секунду. Все просто, но такими оценками пользуются, разве что заявляя в прессе о будущих планах по построению суперкомпьютера.
Практическое измерение заключается в запуске бенчмарка Linpack. Бенчмарк осуществляет операцию умножения матрицы на матрицу несколько десятков раз и вычисляет усредненное значение времени выполнения теста. Так как количество FP операций в имплементации алгоритма известно заранее, то разделив одно значение на другое, получим искомое FLOPS. Библиотека Intel MKL (Math Kernel Library) содержит пакет LAPAСK, — пакет библиотек для решения задач линейной алгебры. Бенчмарк построен на основе этого пакета. Cчитается, что его эффективность находится на уровне 90% от теоретически возможной, что позволяет бенчмарку считаться «эталонным измерением». Отдельно Intel Optimized LINPACK Benchmark для Windows, Linux и MacOS можно качать здесь, либо взять в директории composerxe/mkl/benchmarks, если у вас установлена Intel Parallel Studio XE.
Очевидно, что разработчики высокопроизводительных приложений хотели бы оценить эффективность имплементации своих алгоритмов, используя показатель FLOPS, но уже померянный для своего приложения. Сравнение измеренного FLOPS с «эталонным» дает представление о том, насколько далека производительность их алгоритма от идеальной и каков теоретический потенциал ее улучшения. Для этого всего-навсего нужно знать минимальное количество FP операций, требуемое для выполнения алгоритма, и точно измерить время выполнения программы (ну или ее части, выполняющей оцениваемый алгоритм). Такие результаты, наряду с измерениями характеристик шины памяти, нужны для того, чтобы понять, где реализация алгоритма упирается в возможности аппаратной системы и что является лимитирующим фактором: пропускная способность памяти, задержки передачи данных, производительность алгоритма, либо системы.
Ну а теперь давайте покопаемся в деталях, в которых, как известно, все зло. У нас есть три оценки/измерения FLOPS: теоретическая, бенчмарк и программа. Рассмотрим особенности вычисления FLOPS для каждого случая.
Теоретическая оценка FLOPS для системы
Чтобы понять, как подсчитывается количество одновременных операций в процессоре, давайте взглянем на устройство блока out-of-order в конвеере процессора Intel Sandy Bridge.
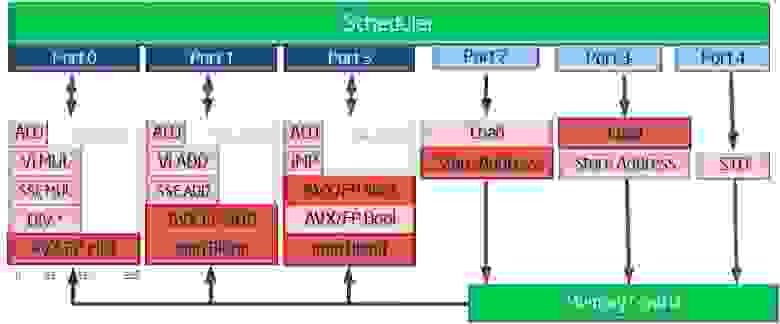
Здесь у нас 6 портов к вычислительным устройствам, при этом, за один цикл (или такт процессора) диспетчером может быть назначено на выполнение до 6 микроопераций: 3 операции с памятью и 3 вычислительные. Одновременно могут выполняться одна операция умножения (MUL ) и одна сложения (ADD ), как в блоках x87 FP, так и в SSE, либо AVX. С учетом ширины SIMD регистров 256 бит мы может получить следующие результаты:

8 MUL (32-bit) и 8 ADD (32-bit): 16 SP FLOP/cycle, то есть 16 операций с плавающей точкой одинарной точности за один такт.
4 MUL (64-bit) и 4 ADD (64-bit): 8 DP FLOP/cycle, то есть 8 операций с плавающей точкой двойной точности за один такт.
Теоретическое пиковое значение FLOPS для доступного мне 1-сокетного Xeon E3-1275 (4 cores @ 3.574GHz) составляет:
16 (FLOP/cycle)*4*3.574 (Gcycles/sec)= 228 GFLOPS SP
8 (FLOP/cycle)*4*3.574 (Gcycles/sec)= 114 GFLOPS DP
Запуск бенчмарка Linpack
Запускам бенчмарк из пакета Intel MKL на системе и получаем следующие результаты (порезано для удобства просмотра):
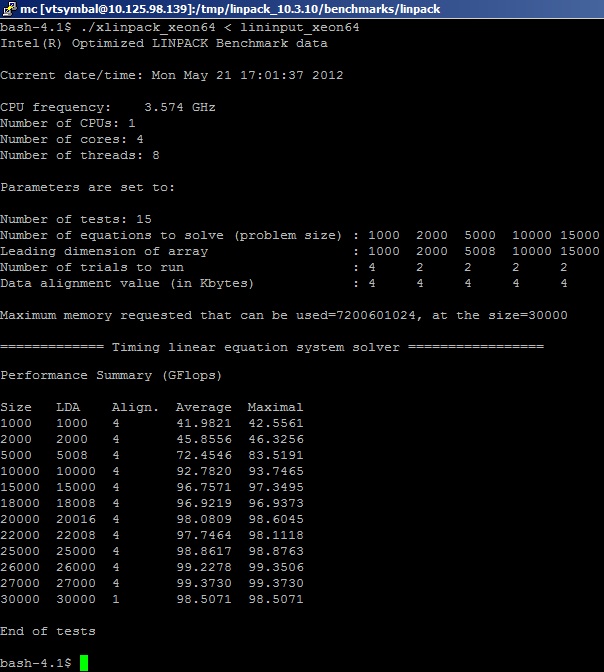
Здесь нужно сказать, как именно учитываются FP операции в бенчмарке. Как уже упоминалось, тест заранее «знает» количество операций MUL и ADD, которые необходимы для перемножения матриц. В упрощенном представлении: производится решение системы линейных уравнений Ax=b (несколько тысяч штук) путем перемножения плотных матриц действительных чисел (real8) размером MxK, а количество операций сложения и умножения, необходимых для реализации алгоритма, считается (для симметричной матрицы) Nflop = 2*(M^3)+(M^2). Вычисления производятся для чисел с двойной точностью, как и для большинства бенчмарков. Сколько операций с плавающей точкой действительно выполняется в реализации алгоритма, пользователей не волнует, хотя они догадываются, что больше. Это связано с тем, что выполняется декомпозиция матриц по блокам и преобразование (факторизация) для достижения максимальной производительности алгоритма на вычислительной платформе. То есть нам нужно запомнить, что на самом деле значение физических FLOPS занижено за счет неучитывания лишних операций преобразования и вспомогательных операций типа сдвигов.
Оценка FLOPS программы
Чтобы исследовать соизмеримые результаты, в качестве нашего высокопроизводительного приложения будем использовать пример перемножения матриц, сделанный «своими руками», то есть без помощи математических гуру из команды разработчиков MKL Performance Library. Пример реализации перемножения матриц, написанный на языке С, можно найти в директории Samples пакета Intel VTune Amplifier XE. Воспользуемся формулой Nflop=2*(M^3) для подсчета FP операций (исходя из базового алгоритма перемножения матриц) и померим время выполнения перемножения для случая алгоритма multiply3 при размере симметричных матриц M=4096. Для того, чтобы получить эффективный код, используем опции оптимизации –O3 (агрессивная оптимизация циклов) и –xavx (использовать инструкции AVX) С-компилятора Intel для того, чтобы сгенерировались векторные SIMD-инструкции для исполнительных устройств AVX. Компилятор нам поможет узнать, векторизовался ли цикл перемножения матрицы. Для этого укажем опцию –vec-report3. В результатах компиляции видим сообщения оптимизатора: «LOOP WAS VECTORIZED» напротив строки с телом внутреннего цикла в файле multiply.c.
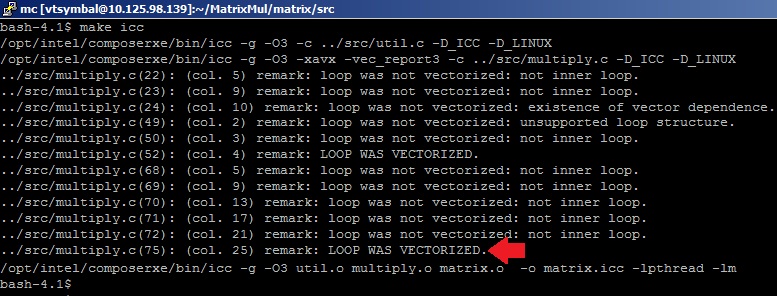
На всякий случай проверим, какие инструкции сгенерированы компилятором для цикла перемножения.
$icl –g –O3 –xavx –S
По тэгу __tag_value_multiply3 ищем нужный цикл — инструкции правильные.
$vi muliply3.s 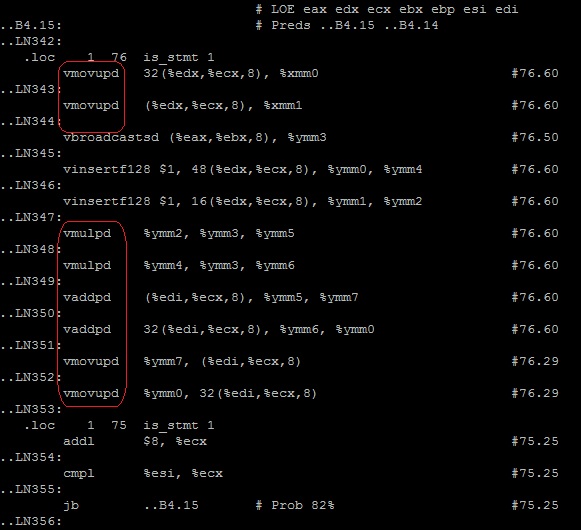
Результат выполнения программы (
7 секунд) 
нам дает следующее значение FLOPS = 2*4096*4096*4096/7[s] = 19.6 GFLOPS
Результат, конечно, очень далек от того, что получается в Linpack, что объясняется исключительно квалификционной пропастью между автором статьи и разработчиками библиотеки MKL.
Ну, а теперь дессерт! Собственно то, ради чего я затеял свое исследование этой, вроде бы скучной и давно избитой, темы. Новый метод измерения FLOPS.
Измерение FLOPS программы
Существуют задачи в линейной алгебре, программную имплементацию решения которых очень сложно оценить в количестве FP операций, в том смысле, что нахождение такой оценки само является нетривиальной математической задачей. И тут мы, что называется, приехали. Как считать FLOPS для программы? Есть два пути, оба экспериментальных: трудный, дающий точный результат, и легкий, но обеспечивающий приблизительную оценку. В первом случае нам придется взять некую базовую программную имплементацию решения задачи, скомпилировать ее в ассемблерные инструкции и, выполнив их на симуляторе процессора, посчитать количество FP операций. Звучит так, что резко хочется пойти легким, но недостоверным путем. Тем более, что если ветвление исполнения задачи будет зависеть от входных данных, то вся точность оценки сразу поставится под сомнение.
Идея легкого пути состоит в следующем. Почему бы не спросить сам процессор, сколько он выполнил FP инструкций. Процессорный конвеер, конечно же, об этом не ведает. Зато у нас есть счетчики производительности (PMU – вот тут про них интересно), которые умеют считать, сколько микроопераций было выполнено на том или ином вычислительном блоке. С такими счетчиками умеет работать VTune Amplifier XE.
Несмотря на то, что VTune имеет множество встроенных профилей, специального профиля для измерения FLOPS у него пока нет. Но никто не мешает нам создать наш собственный пользовательский профиль за 30 секунд. Не утруждая вас основами работы с интерфейсом VTune (их можно изучить в прилагающимся к нему Getting Started Tutorial), сразу опишу процесс создания профиля и сбора данных.
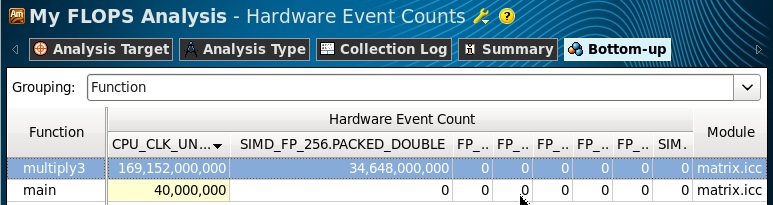
Далее мы просто подсчитываем значения FLOPS по формулам. Данные у нас были собраны для всех процессоров, поэтому умножение на их количество здесь не требуется. Операции данными двойной точности выполняются одновременно над четырмя 64-битными DP операндами в 256-битном регистре, поэтому умножаем на коэффициент 4. Данные с одинарной точностью, соответственно, умножаем на 8. В последней формуле не умножаем количество инструкций на коэффициент, так как операции сопроцессора x87 выполняются только со скалярными величинами. Если в программе выполняется несколько разных типов FP операций, то их количество, умноженное на коэффициенты, суммируется для получения результирующего FLOPS.
FLOPS = 4 * SIMD_FP_256.PACKED_DOUBLE / Elapsed Time
FLOPS = 8 * SIMD_FP_256.PACKED_SINGLE / Elapsed Time
FLOPS = (FP_COMP_OPS_EXE.x87) / Elapsed Time
В нашей программе выполнялись только AVX инструкции, поэтому в результатах есть значение только одного счетчика SIMD_FP_256.PACKED_DOUBLE.
Удостоверимся, что данные события собраны для нашего цикла в функции multiply3 (переключившись в Source View):

FLOPS = 4 *34.6Gops/7s = 19.7 GFlops
Значение вполне соответствует оценочному, подсчитанному в предыдущем пункте. Поэтому с достаточной долей точности можно говорить о том, что результаты оценочного метода и измерительного совпадают. Однако, существуют случаи, когда они могут не совпадать. При определенном интересе читателей, я могу заняться их исследованием и рассказать, как использовать более сложные и точные методы. А взамен очень хочется услышать о ваших случаях, когда вам требуется измерение FLOPS в программах.
Заключение
FLOPS – единица измерения производительности вычислительных систем, которая характеризует максимальную вычислительную мощность самой системы для операций с плавающей точкой. FLOPS может быть заявлена как теоретическая, для еще не существующих систем, так и измерена с помощью бенчмарков. Разработчики высокопроизводительных программ, в частности, решателей систем линейных дифференциальных уравнений, оценивают производительность реализации своих алгоритмов в том числе и по значению FLOPS программы, вычисленному с помощью теоретически/эмпирически известного количества FP операций, необходимых для выполнения алгоритма, и измеренному времени выполнения теста. Для случаев, когда сложность алгоритма не позволяет оценить количество FP операций алгоритма, их можно измерить с помощью счетчиков производительности, встроенных в микропроцессоры Intel.