Классификация
Материал из MachineLearning.
Классификация — один из разделов машинного обучения, посвященный решению следующей задачи. Имеется множество объектов (ситуаций), разделённых некоторым образом на классы. Задано конечное множество объектов, для которых известно, к каким классам они относятся. Это множество называется обучающей выборкой. Классовая принадлежность остальных объектов не известна. Требуется построить алгоритм, способный классифицировать произвольный объект из исходного множества.
Классифицировать объект — значит, указать номер (или наименование класса), к которому относится данный объект.
Классификация объекта — номер или наименование класса, выдаваемый алгоритмом классификации в результате его применения к данному конкретному объекту.
В математической статистике задачи классификации называются также задачами дискриминантного анализа.
В машинном обучении задача классификации относится к разделу обучения с учителем. Существует также обучение без учителя, когда разделение объектов обучающей выборки на классы не задаётся, и требуется классифицировать объекты только на основе их сходства друг с другом. В этом случае принято говорить о задачах кластеризации или таксономии, и классы называть, соответственно, кластерами или таксонами.
Содержание
Типология задач классификации
Типы входных данных
Классификацию сигналов и изображений называют также распознаванием образов.
Типы классов
Классификация: формальная постановка
Вероятностная постановка задачи
Признаковое пространство
В зависимости от множества признаки делятся на следующие типы:
Часто встречаются прикладные задачи с разнотипными признаками, для их решения подходят далеко не все методы.
Примеры прикладных задач
Задачи медицинской диагностики
В роли объектов выступают пациенты. Признаки характеризуют результаты обследований, симптомы заболевания и применявшиеся методы лечения. Примеры бинарных признаков: пол, наличие головной боли, слабости. Порядковый признак — тяжесть состояния (удовлетворительное, средней тяжести, тяжёлое, крайне тяжёлое). Количественные признаки — возраст, пульс, артериальное давление, содержание гемоглобина в крови, доза препарата. Признаковое описание пациента является, по сути дела, формализованной историей болезни. Накопив достаточное количество прецедентов в электронном виде, можно решать различные задачи:
Ценность такого рода систем в том, что они способны мгновенно анализировать и обобщать огромное количество прецедентов — возможность, недоступная специалисту-врачу.
Предсказание месторождений полезных ископаемых
Признаками являются данные геологической разведки. Наличие или отсутствие тех или иных пород на территории района кодируется бинарными признаками. Физико-химические свойства этих пород могут описываться как количественными, так и качественными признаками. Обучающая выборка составляется из прецедентов двух классов: районов известных месторождений и похожих районов, в которых интересующее ископаемое обнаружено не было. При поиске редких полезных ископаемых количество объектов может оказаться намного меньше, чем количество признаков. В этой ситуации плохо работают классические статистические методы. Задача решается путём поиска закономерностей в имеющемся массиве данных. В процессе решения выделяются короткие наборы признаков, обладающие наибольшей информативностью — способностью наилучшим образом разделять классы. По аналогии с медицинской задачей, можно сказать, что отыскиваются «синдромы» месторождений. Это важный побочный результат исследования, представляющий значительный интерес для геофизиков и геологов.
Оценивание кредитоспособности заёмщиков
Эта задача решается банками при выдаче кредитов. Потребность в автоматизации процедуры выдачи кредитов впервые возникла в период бума кредитных карт 60-70-х годов в США и других развитых странах. Объектами в данном случае являются физические или юридические лица, претендующие на получение кредита. В случае физических лиц признаковое описание состоит из анкеты, которую заполняет сам заёмщик, и, возможно, дополнительной информации, которую банк собирает о нём из собственных источников. Примеры бинарных признаков: пол, наличие телефона. Номинальные признаки — место проживания, профессия, работодатель. Порядковые признаки — образование, занимаемая должность. Количественные признаки — сумма кредита, возраст, стаж работы, доход семьи, размер задолженностей в других банках. Обучающая выборка составляется из заёмщиков с известной кредитной историей. В простейшем случае принятие решений сводится к классификации заёмщиков на два класса: «хороших» и «плохих». Кредиты выдаются только заёмщикам первого класса. В более сложном случае оценивается суммарное число баллов (score) заёмщика, набранных по совокупности информативных признаков. Чем выше оценка, тем более надёжным считается заёмщик. Отсюда и название — кредитный скоринг. На стадии обучения производится синтез и отбор информативных признаков и определяется, сколько баллов назначать за каждый признак, чтобы риск принимаемых решений был минимален. Следующая задача — решить, на каких условиях выдавать кредит: определить процентную ставку, срок погашения, и прочие параметры кредитного договора. Эта задача также может быть решения методами обучения по прецедентам.
Общие понятия
Содержание
Понятие машинного обучения в искусственном интеллекте [ править ]
Одним из первых, кто использовал термин «машинное обучение», был изобретатель первой самообучающейся компьютерной программы игры в шашки А. Л. Самуэль в 1959 г. [1]
| Определение: |
| Машинное обучение (англ. Machine learning) — процесс, который даёт возможность компьютерам обучаться выполнять что-то без явного написания кода. |
Это определение не выдерживает критики, так как не понятно, что означает наречие «явно». Более точное определение дал намного позже Т. М. Митчелл. [2]
Задача обучения [ править ]
$X$ — множество объектов (англ. object set, or input set)
$Y$ — множество меток классов (англ. label set, or output set)
$\hat y∶ X → Y$ — неизвестная зависимость (англ. unknown target function (dependency))
Признаки [ править ]
[math] F = ||f_j(x_i)||_ <[l \times n]>= \begin
Типы задач [ править ]
Классификация (англ. classification)
Цель: научиться определять, к какому классу принадлежит объект.
Примеры: распознавание текста по рукописному вводу; определение того, находится на фотографии человек или кот; определение, является ли письмо спамом.
Методы: метод ближайших соседей, дерево решений, логистическая регрессия, метод опорных векторов, байесовский классификатор, cверточные нейронные сети.
Восстановление регрессии (англ. regression)
Цель: получать прогноз на основе выборки объектов.
Примеры: предсказание стоимости акции через полгода; предсказание прибыли магазина в следующем месяце; предсказание качества вина на слепом тестировании.
Методы: линейная регрессия, дерево решений, метод опорных векторов.
Цель: научиться по множеству объектов получать множество рейтингов, упорядоченное согласно заданному отношению порядка.
Примеры: выдача поискового запроса; подбор интересных новостей для пользователя.
Методы: поточечный подход, попарный подход, списочный подход.
Кластеризация (англ. clustering)
Цель: разбить множество объектов на подмножества (кластеры) таким образом, чтобы объекты из одного кластера были более похожи друг на друга, чем на объекты из других кластеров по какому-либо критерию.
Примеры: разбиение клиентов сотового оператора по платёжеспособности; разбиение космических объектов на похожие (галактики, планеты, звезды).
Методы: иерархическая кластеризация, эволюционные алгоритмы кластеризации, EM-алгоритм.
Вспомогательные типы задач [ править ]
Уменьшение размерности (англ. dimensionality reduction)
Выявление аномалий (англ. anomaly detection)
Цель: научиться выявлять аномалии в данных. Отличительная особенность задачи от классификации — примеров аномалий для тренировки модели очень мало, либо нет совсем; поэтому для ее решения необходимы специальные методы.
Примеры: определение мошеннических транзакций по банковской карте; обнаружение событий, предвещающих землетрясение.
Методы: экстремальный анализ данных, аппроксимирующий метод, проецирующие методы.
Классификация задач машинного обучения [ править ]
Обучение с учителем (англ. Supervised learning [3] ) [ править ]
Обучение без учителя (англ. Unsupervised learning) [ править ]
Изучает широкий класс задач обработки данных, в которых известны только описания множества объектов (обучающей выборки), и требуется обнаружить внутренние взаимосвязи, зависимости, закономерности, существующие между объектами. Т.е. тренировочные данные доступны все сразу, но ответы для поставленной задачи неизвестны.
Задачи, которые могут решаться этим способом: кластеризация, нахождение ассоциативных правил, выдача рекомендаций (например, реклама), уменьшение размерности датасета, обработка естественного языка.
Обучение с частичным привлечением учителя (англ. Semi-supervised learning [4] ) [ править ]
Занимает промежуточное положение между обучением с учителем и без учителя. Каждый прецедент представляет собой пару «объект, ответ», но ответы известны только на части прецедентов (Размечено мало, либо малоинформативная часть).
Примером частичного обучения может послужить сообучение: два или более обучаемых алгоритма используют один и тот же набор данных, но каждый при обучении использует различные — в идеале некоррелирующие — наборы признаков объектов.
Обучение с подкреплением (англ. Reinforcement learning) [ править ]
Частный случай обучения с учителем, сигналы подкрепления (правильности ответа) выдаются не учителем, а некоторой средой, с которой взаимодействует программа. Размеченность данных зависит от среды.
Окружение обычно формулируется как марковский процесс принятия решений (МППР) с конечным множеством состояний, и в этом смысле алгоритмы обучения с подкреплением тесно связаны с динамическим программированием. Вероятности выигрышей и перехода состояний в МППР обычно являются величинами случайными, но стационарными в рамках задачи.
При обучении с подкреплением, в отличие от обучения с учителем, не предоставляются верные пары «входные данные-ответ», а принятие субоптимальных решений (дающих локальный экстремум) не ограничивается явно. Обучение с подкреплением пытается найти компромисс между исследованием неизученных областей и применением имеющихся знаний (англ. exploration vs exploitation tradeoff).
Активное обучение (англ. Active learning) [ править ]
Отличается тем, что обучаемый имеет возможность самостоятельно назначать следующий прецедент, который станет известен. Применяется когда получение истиной метки для объекта затруднительно. Поэтому алгоритм должен уметь определять, на каких объектах ему надо знать ответ, чтобы лучше всего обучиться, построить наилучшую модель.
Обучение в реальном времени (англ. Online learning) [ править ]
Может быть как обучением с учителем, так и без учителя. Специфика в том, что тренировочные данные поступают последовательно. Требуется немедленно принимать решение по каждому прецеденту и одновременно доучивать модель зависимости с учётом новых прецедентов. Здесь существенную роль играет фактор времени.
Примеры задач [ править ]
Признаками являются данные геологической разведки.
Обучающая выборка состоит из двух классов:
При поиске редких полезных ископаемых количество объектов может оказаться намного меньше, чем количество признаков. В этой ситуации плохо работают классические статистические методы. Задача решается путём поиска закономерностей в имеющемся массиве данных. В процессе решения выделяются короткие наборы признаков, обладающие наибольшей информативностью — способностью наилучшим образом разделять классы («синдромы» месторождений).
Эта задача решается банками при выдаче кредитов. Объектами в данном случае являются физические или юридические лица, претендующие на получение кредита.
В случае физических лиц признаковое описание состоит из:
Можно выделить следующие признаки:
Обучающая выборка составляется из заёмщиков с известной кредитной историей.
На стадии обучения производится синтез и отбор информативных признаков и определяется, сколько баллов назначать за каждый признак, чтобы риск принимаемых решений был минимален. Чем выше суммарное число баллов заёмщика, набранных по совокупности информативных признаков, тем более надёжным считается заёмщик.
В роли объектов выступают пациенты. Признаки характеризуют результаты обследований, симптомы заболевания и применявшиеся методы лечения.
Признаковое описание пациента является, по сути дела, формализованной историей болезни.
Накопив достаточное количество данных, можно решать различные задачи:
Ценность такого рода систем в том, что они способны мгновенно анализировать и обобщать огромное количество прецедентов — возможность, недоступная специалисту-врачу.
📊 Построение и отбор признаков. Часть 1: feature engineering

Что такое признаки (features) и для чего они нужны?
Признаки могут быть следующих видов:
Стоит отметить, что для задач машинного обучения нужны только те «фичи», которые на самом деле влияют на итоговый результат. Определить и сгенерировать такие признаки вам поможет эта статья.
Что такое построение признаков?
Например, в базе данных интернет-магазина есть таблица «Покупатели», содержащая одну строку для каждого посетившего сайт клиента.

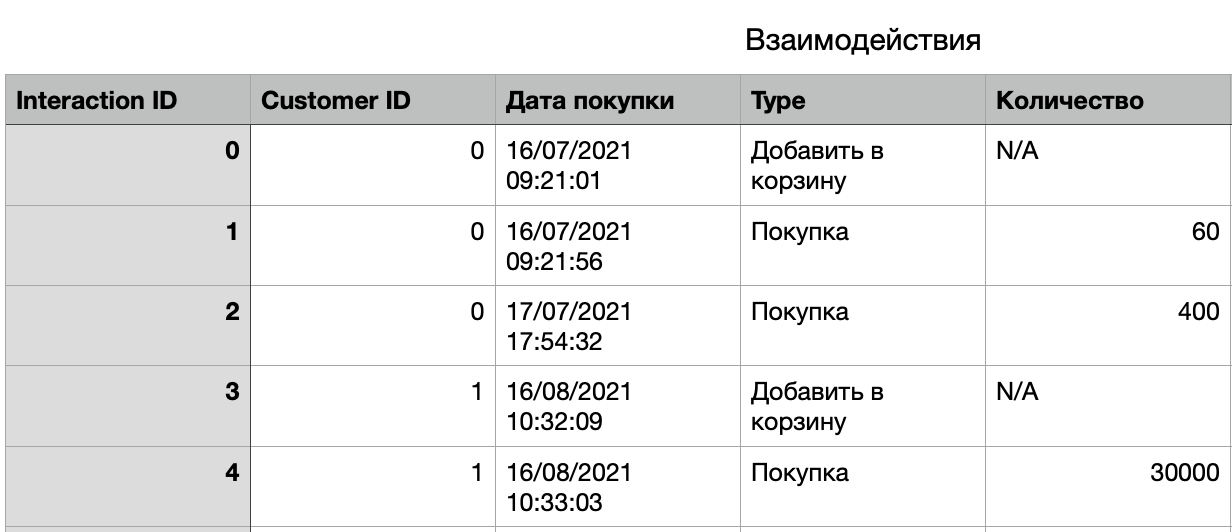
Чтобы повысить предсказательную способность, нам необходимо воспользоваться данными в таблице взаимодействий. Отбор признаков делает это возможным. Мы можем рассчитать статистику для каждого клиента, используя все значения в таблице «Взаимодействия» с идентификатором этого клиента. Вот несколько потенциально полезных признаков, или же «фич», которые помогут нам в решении задачи:
Следует обратить внимание, что данный процесс уникален для каждого случая использования и набора данных.
Этот тип инжиниринга признаков необходим для эффективного использования алгоритмов машинного обучения и построения прогностических моделей.
Построение признаков на табличных данных
Удаление пропущенных значений
Отсутствующие значения – одна из наиболее распространенных проблем, с которыми вы можете столкнуться при попытке подготовить данные. Этот фактор очень сильно влияет на производительность моделей машинного обучения.
Самое простое решение для пропущенных значений – отбросить строки или весь столбец. Оптимального порога для отбрасывания не существует, но вы можете использовать 70% в качестве значения и отбросить строки со столбцами, в которых отсутствуют значения, превышающие этот порог.
Заполнение пропущенных значений
В качестве другого примера: у вас есть столбец, который показывает количество посещений клиентов за последний месяц. Тут отсутствующие значения могут быть заменены на 0.
За исключением вышеперечисленного, лучший способ заполнения пропущенных значений – использовать медианы столбцов. Поскольку средние значения столбцов чувствительны к значениям выбросов, медианы в этом отношении будут более устойчивыми.
Замена пропущенных значений максимальными
Замена отсутствующих значений на максимальное значение в столбце будет хорошим вариантом для работы только в случае, когда мы разбираемся с категориальными признаками. В других ситуациях настоятельно рекомендуется использовать предыдущий метод.
Обнаружение выбросов
Другой математический метод обнаружения выбросов – использование процентилей. Вы принимаете определенный процент значения сверху или снизу за выброс.
Ключевым моментом здесь является повторная установка процентного значения, и это зависит от распределения ваших данных, как упоминалось ранее.
Ограничение выбросов
С другой стороны, ограничение может повлиять на распределение данных и качество модели, поэтому лучше придерживаться золотой середины.
Логарифмическое преобразование
Важное примечание: данные, которые вы применяете, должны иметь только положительные значения, иначе вы получите ошибку.
Быстрое кодирование (One-Hot encoding)
Этот метод распределяет значения в столбце по нескольким столбцам флагов и присваивает им 0 или 1. Бинарные значения выражают связь между сгруппированным и закодированным столбцом. Этот метод изменяет ваши категориальные данные, которые сложно понять алгоритмам, в числовой формат. Группировка происходит без потери какой-либо информации, например:
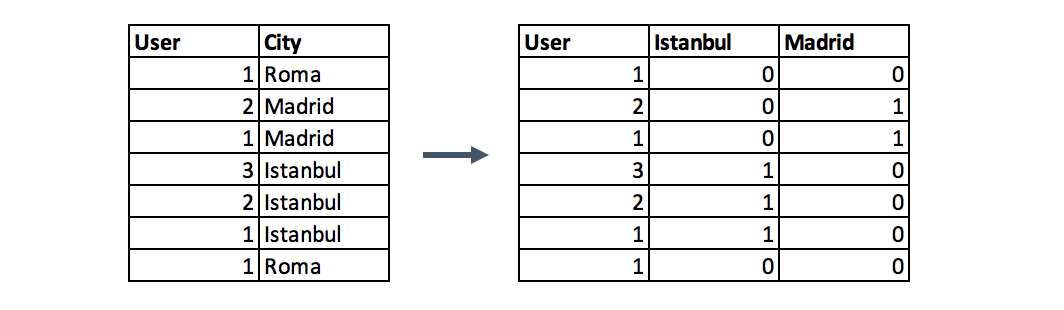
Приведенная ниже функция отражает использование метода быстрого кодирования с вашими данными.
Масштабирование признаков
В большинстве случаев числовые характеристики набора данных не имеют определенного диапазона и отличаются друг от друга.
Например, столбцы возраста и месячной зарплаты будут иметь совершенно разный диапазон.
Как сравнить эти два столбца, если это необходимо в нашей задаче? Масштабирование решает эту проблему, так как после данной операции элементы становятся идентичными по диапазону.
Существует два распространенных способа масштабирования:
В данном случае все значения будут находиться в диапазоне от 0 до 1. Дискретные бинарные значения определяются как 0 и 1.
Масштабирует значения с учетом стандартного отклонения. Если стандартное отклонение функций другое, их диапазон также будет отличаться друг от друга. Это снижает влияние выбросов в элементах. В следующей формуле стандартизации среднее значение показано как μ, а стандартное отклонение показано как σ.
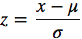
Работа с текстом
Перед тем как работать с текстом, его необходимо разбить на токены – отдельные слова. Однако делая это слишком просто, мы можем потерять часть смысла. Например, «Великие Луки» это не два токена, а один.
В коде алгоритм выглядит гораздо проще, чем на словах:
Работа с изображениями
Чтобы адаптировать ее под свою задачу, работающие в области науки о данных инженеры практикуют fine tuning (тонкую настройку). Ликвидируются последние слои нейросети, вместо них добавляются новые, подобранные под нашу конкретную задачу, и сеть дообучается на новых данных.
Пример подобного шаблона:
Заключение
На практике процесс построения фич может быть самым разнообразным: решение проблемы пропущенных значений, обнаружение выбросов, превращение текста в вектор (с помощью продвинутой обработки естественного языка, которая отображает слова в векторное пространство) – лишь некоторые примеры из этой области.
Решение задачи бинарной классификации в пакете машинного обучения «XGboost»

В этой статье речь пойдет о задачи бинарной классификации объектов и ее реализации в одном из наиболее производительных пакетов машинного обучения «R» — «XGboost» (Extreme Gradient Boosting).
В реальной жизни мы довольно часто сталкиваемся с классом задач, где объектом предсказания является номинативная переменная с двумя градациями, когда нам необходимо предсказать результат некого события или принять решения в бинарном выражении на основании модели данных. Например, если мы оцениваем ситуацию на рынке и нашей целью является принятие однозначного решения, имеет ли смысл инвестировать в определенный инструмент в данный момент времени, купит ли покупатель исследуемый продукт или нет, расплатится ли заемщик по кредиту или уволится ли сотрудник из компании в ближайшее время и.т.д.
В общем случае бинарная классификация применяется для предсказания вероятности возникновения некоторого события по значениям множества признаков. Для этого вводится так называемая зависимая переменная (исход события), принимающая лишь одно из двух значений (0 или 1), и множество независимых переменных (также называемых признаками, предикторами или регрессорами).
Сразу оговорюсь, что в «R» существует несколько линейных функций для решения подобных задач, таких как «glm» из стандартного пакета функций, но здесь мы рассмотрим более продвинутый вариант бинарной классификации, имплементированный в пакете «XGboost». Эта модель, многократный победитель соревнований Kaggle, основана на построении бинарных деревьев решений способна поддерживать многопоточную обработку данных. Об особенностях реализации семейства моделей «Gradient Boosting» можно прочитать здесь:
Возьмем тестовый набор данных (Train) и построим модель для предсказания выживаемости пассажиров при катастрофе :
Если после преобразования матрица содержит много нулей, то такой массив данных нужно предварительно преобразовать в sparse matrix — в таком виде данные займут намного меньше места, а соответственно и время обработки данных намного сократится. Здесь нам поможет библиотека ‘Matrix’ на сегодняшний день последняя доступная версия 1.2-6 содержит в себе набор функция для преобразования в dgCMatrix на колоночной основе.
В случае, когда уже уплотненная матрица (sparse matrix) после всех преобразований не помещается в оперативной памяти, то в таких случаях используют специальную программу “Vowpal Wabbit”. Это внешняя программа, которая может обработать датасеты любых размеров, читая из многих файлов или баз данных. “Vowpal Wabbit” представляет собой оптимизированную платформу для параллельного машинного обучения, разработанную для распределенных вычислений компанией “Yahoo!” Про нее довольно подробно можно прочесть по этим ссылкам:
Использование разреженных матриц дает нам возможность строить модель с использованием текстовых переменных с предварительным их преобразованием.
Итак, для построения матрицы предикторов сначала загружаем необходимые библиотеки:
При конвертации в матрицу все категориальные переменные будут транспониваны, соответственно функция со стандартным бустером включит их значения в модель. Первое что нужно сделать, это удалить из набора данных переменные с уникальными значениями, такими как “Passenger ID”, “Name” и “Ticket Number”. Такие же действия проводим и с тестовым набором данных, по которым будут рассчитывается прогнозные исходы. Для наглядности я загрузил данные из локальных файлов, которые скачал в соответствующем датасете Kaggle. Для модели, ним понадобятся следующие колонки таблицы:
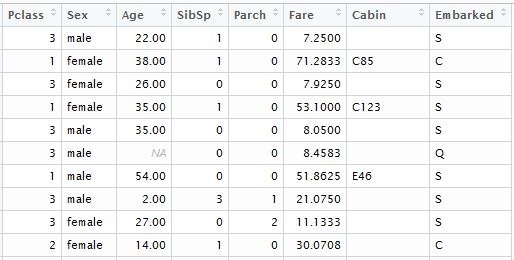
отдельно формируем вектор известных исходов для обучения модели
Теперь необходимо выполнить преобразование данных, дабы при обучении модели в учет были приняты статистически значимые переменные. Выполним следующие преобразования:
Заменим переменные содержащие категориальные данные на числовые значения. При этом нужно учитывать что упорядоченные категории, такие как ‘good’, ‘normal’, ‘bad’ можно заменить на 0,1,2. Не упорядоченные данные с относительно небольшой селективностью, такие как ‘gender’ или ‘Country Name’ можно оставить факторными без изменения, после преобразование в матрицу они транспонируются в соответствующее количество столбцов с нулями и единицами. Для числовых переменных, необходимо обработать все неприсвоенные и пропущенные значения. Здесь есть как минимум три варианта: их можно подменить на 1, 0 либо более приемлемый вариант будет замена на среднее значение по колонке этой переменной.
При использовании пакета “XGboost” со стандартным бустером (gbtree), масштабирование переменных можно не выполнять, в отличии от других линейных методов, таких как “glm” или “xgboost” c линейным бустером (gblinear).
Основную информацию о пакете можно найти по следующим ссылкам:
Возвращаясь к нашему коду, в результате мы получили таблицу следующего формата:

далее, заменяем все пропущенные записи на среднее арифметическое значение по столбцу предиктора
после предварительной обработки делаем преобразование в «dgCMatrix»:
Имеет смысл создать отдельную функцию для предварительной обработки предикторов и преобразования в sparse.model.matrix формат, например вариант с «for» циклом приведен ниже. C целью оптимизации производительности можно векторизовать выражение используя функцию «apply».
Тогда воспользуемся нашей функцией и преобразуем фактическую и тестовую таблицы в разреженные матрицы:

Для построения модели нам потребуется два набора данных: матрица данных, которую мы только что создали и вектор фактических исходов с бинарным значением (0,1).
Функция «xgboost» является наиболее удобной в использовании. В “XGBoost” имплементирован стандартный бустер основан на бинарных деревьях решений.
Для использования “XGboost”, мы должны выбрать один из трех параметров: общие параметры, параметры бустера и параметров назначения:
• Общие параметры – определяем, какой бустер будет использован, линейный или стандартный.
Остальные параметры бустера зависят от того, какой бустер мы выбрали на первом шаге:
• Параметры задач обучения – определяем назначение и сценарий обучения
• Параметры командной строки — используются для определения режима командной строки при использовании “xgboost.”.
Общий вид функции “xgboost” который мы используем:
«data» – данные матричном формате ( «matrix», «dgCMatrix», local data file or «xgb.DMatrix».)
«label» – вектор зависимой переменной. Если данное поле было составляющей исходной таблицы параметров, то перед обработкой и преобразованием в матрицу, его следует исключить, дабы избежать транзитивности связей.
«nrounds» –количество построенных деревьев решений в финальной модели.
«objective» – через данный параметр мы передаем задачи и назначения обучения модели. Для логистической регрессии существуют 2 варианта:
«reg:logistic» – логистическая регрессия с непрерывной величиной оценки от 0 до 1;
«binary:logistic» – логистическая регрессия с бинарной величиной предсказания. Для этого параметра можно задать специфическую пороговую величину перехода от 0 к 1. По умолчанию это значение 0.5.
Детально про параметризацию модели можно прочесть по этой ссылке
при желании можно извлечь структуру деревьев с помощью функции xgb.model.dt.tree( model = xgb). Далее, используем стандартную функцию “predict” для формирования прогнозного вектора:
и наконец, сохраним данные в приемлемом для чтения формате
добавляя вектор предсказанных исходов, получаем таблицу следующего вида:

Теперь немного вернемся и вкратце рассмотрим саму модель, которую мы только что создали. Для отображения деревьев решения, можно воспользоваться функциями «xgb.model.dt.tree» и «xgb.plot.tree». Так, последняя функция выдаст нам список выбранных деревьев с коэффициентом подгонки модели:

Используя функцию xgb.plot.tree мы также увидим графическое представление деревьев, хотя нужно отметить что в текущей версии, оно далеко не лучшим способом имплементировано в данной функции и является мало полезным. По этому, для наглядности, мне пришлось воспроизвести вручную элементарное дерево решений на базе стандартной модели данных Train.
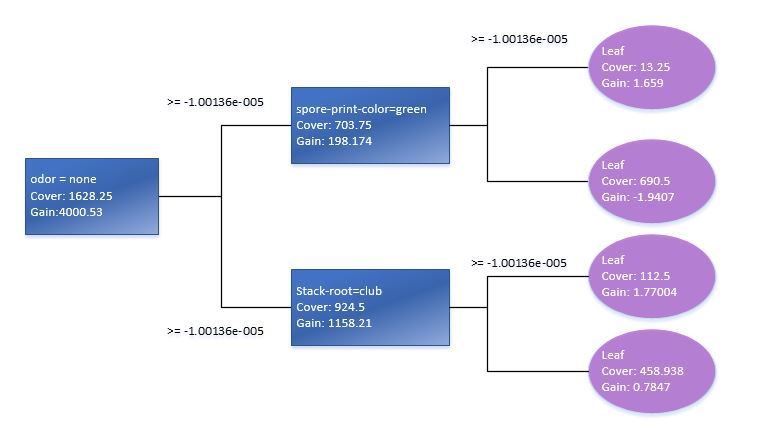
Проверка статистической значимости переменных в модели подскажет нам как оптимизировать матрицу предикторов для обучения XGB-модели. Лучше всего использовать функцию xgb.plot.importance в которую мы передадим агрегированную таблицу важности параметров.

Итак, мы рассмотрели одну из возможных реализаций логистической регрессии на базе пакета функции “xgboost” со стандартным бустером. На данный момент я рекомендую использовать пакет “XGboost” как наиболее продвинутую группу моделей машинного обучения. В настоящие время предиктивные модели на базе логики “XGboost” широко используются в финансовом и рыночном прогнозировании, маркетинге и многих других областях прикладной аналитики и машинного интеллекта.



