Искусственный интеллект, машинное обучение и глубокое обучение: в чём разница
Компьютер запросто диагностирует рак, управляет автомобилем и умеет обучаться. Почему же машины пока не захватили власть над человечеством?


Мы пользуемся Google-картами, позволяем сайтам подбирать для нас интересные фильмы и советовать, что купить. И, в общем-то, слышали, что под капотом всех этих умных вещей — искусственный интеллект, машинное обучение и deep learning. Но сможете ли вы с ходу отличить одно от другого? Разбираемся на примерах.
Что такое искусственный интеллект
Искусственный интеллект (англ. artificial intelligence) — это способность компьютера обучаться, принимать решения и выполнять действия, свойственные человеческому интеллекту.
Кроме того, ИИ — это наука на стыке математики, биологии, психологии, кибернетики и ещё кучи всего. Она изучает технологии, которые позволяют человеку писать «интеллектуальные» программы и учить компьютеры решать задачи самостоятельно. Главная задача ИИ — понять, как устроен человеческий интеллект, и смоделировать его.
В области искусственного интеллекта есть подразделы. К ним относятся робототехника, наука о компьютерном зрении, обработка естественного языка и машинное обучение.
Хотите знать, может ли машина мыслить и чувствовать как человек? Приходите на курс «Философия искусственного интеллекта». Здесь вы получите новые знания об ИИ, обсудите актуальные вопросы с преподавателями и однокурсниками и прокачаете навык публичных выступлений.

Пишет про digital и машинное обучение для корпоративных блогов. Топ-автор в категории «Искусственный интеллект» на Medium. Kaggle-эксперт.
Каким бывает искусственный интеллект
Исследователи обычно делят ИИ на три группы:
Слабый ИИ (Weak, или Narrow AI)
Слабый интеллект — тот, что нам уже удалось создать. Такой ИИ способен решать определённую задачу. Зачастую даже лучше, чем человек. Например, как Deep Blue — компьютерная программа, которая обыграла Гарри Каспарова в шахматы ещё в 1996 году. Но такая Deep Blue не умеет делать ничего другого и никогда этому не научится. Слабый ИИ используют в медицине, логистике, банковском деле, бизнесе:
Это несколько примеров, в реальности применений намного больше.
Сильный ИИ (Strong, или General AI)
Как выглядел бы сильный искусственный интеллект, можно увидеть в игре Detroit: Become Human.
Во вселенной Detroit роботы способны учиться, мыслить, чувствовать, осознавать себя и принимать решения. Одним словом, становятся похожи на человека. А в обычной жизни ближе всего к General AI чат-боты и виртуальные ассистенты, которые имитируют человеческое общение. Здесь ключевое слово — имитируют. Siri или Алиса не думают — и неспособны принимать решения в ситуациях, которым их не обучили. Сильный искусственный интеллект пока остаётся мечтой.
Суперинтеллект (Superintelligence)
Мы не только не создали суперинтеллект, но и не имеем пока что ни малейшего представления, как это сделать и можно ли вообще. Это не просто умные машины, а компьютеры, которые во всём превосходят людей. Проще говоря, что-то из области фантастики.
Машинное обучение: как учится ИИ
Машинное обучение (англ. machine learning) — это один из разделов науки об ИИ. Здесь используются алгоритмы для анализа данных, получения выводов или предсказаний в отношении чего-либо. Вместо того чтобы кодировать набор команд вручную, машину обучают и дают ей возможность научиться выполнять поставленную задачу самостоятельно.
Чтобы машина могла принимать решения, необходимы три вещи:
В машинном обучении много разных алгоритмов. Один из самых простых — линейная регрессия. Её применяют, если есть линейная зависимость между переменными. Пример: чем больше сумма заказа, тем больше вы оставите чаевых. По имеющимся данным можно предсказать сумму чаевых в будущем. В общем-то, простая математика.
Есть байесовские алгоритмы. В их основе применение теоремы Байеса и теории вероятности. Эти алгоритмы используют для работы с текстовыми документами — например, для спам-фильтрации. Программе нужно дать наборы данных по категориям «спам» и «не спам». Дальше алгоритм будет самостоятельно оценивать вероятность того, что слова «Бесплатные туры для пенсионеров» и «Закажи маме тур, пожалуйста» относятся к той или иной категории.
А ещё есть нейронные сети, о них вы наверняка слышали. Они относятся к методам глубокого машинного обучения, и об этом чуть подробнее.
Deep learning: глубокое обучение для разных целей
Глубокое обучение — подраздел машинного обучения. Алгоритмам глубокого обучения не нужен учитель, только заранее подготовленные (размеченные) данные.
Самый популярный, но не единственный метод глубокого обучения, — искусственные нейронные сети (ИНС). Они больше всего похожи на то, как устроен человеческий мозг.
Нейронные сети — это набор связанных единиц (нейронов) и нейронных связей (синапсов). Каждое соединение передаёт сигнал от одного нейрона к другому, как в мозге человека. Обычно нейроны и синапсы организованы в слои, чтобы обрабатывать информацию. Первый слой нейросети — это вход, который получает данные. Последний — выход, результат работы. Например, несколько категорий, к одной из которых мы просим отнести то, что было отправлено на вход. И между ними — скрытые слои, которые выполняют преобразование.
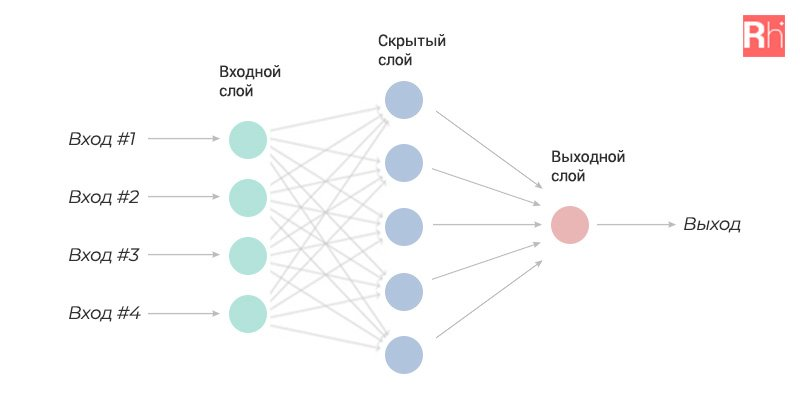
По сути, скрытые слои выполняют какую-то математическую функцию. Мы её не задаём, программа сама учится выводить результат. Можно научить нейросеть классифицировать изображения или находить на изображении нужный объект. Помните, как reCAPTCHA просит найти все изображения грузовиков или светофоров, чтобы доказать, что вы не робот? Нейронная сеть выполняет то же самое, что и наш мозг, — видит знакомые элементы и понимает: «О, кажется, это грузовик!»
А ещё нейросети могут генерировать объекты: музыку, тексты, изображения. Например, компания Botnik скормила нейросети все книги про Гарри Поттера и попросила написать свою. Получился «Гарри Поттер и портрет того, что выглядит как огромная куча пепла». Звучит немного странно, но как минимум с точки зрения грамматики это сочинение имеет смысл.
Сегодня нейронные сети могут применяться практически для любой задачи. Например, при диагностике рака, прогнозировании продаж, идентификации лиц в системах безопасности, машинных переводах, обработке фотографий и музыки.
Чтобы обучить нейросеть, нужны гигантские наборы тщательно отобранных данных. Например, для распознавания сортов огурцов нужно обработать 1,5 млн разных фотографий. Не получится просто слить рандомные картинки или текст из интернета — их нужно подготовить: привести к одному формату и удалить то, что точно не подходит (например, мы классифицируем пиццу, а в наборе данных у нас фото грузовика). На разметку данных — подготовку и систематизацию — уходят тысячи человеко-часов.
Чтобы создать новую нейросеть, требуется задать алгоритм, прогнать через него все данные, протестировать и неоднократно оптимизировать. Это сложно и долго. Поэтому иногда проще воспользоваться более простыми алгоритмами — например, регрессией.
Подведём итоги
Искусственный интеллект — одновременно и наука, которая помогает создавать «умные» машины, и способность компьютера обучаться и принимать решения.
Машинное обучение — одна из областей искусственного интеллекта. МО использует алгоритмы для анализа данных и получения выводов.
А глубокое обучение — лишь один из методов машинного обучения, в рамках которого компьютер учится без учителя подспудно, с помощью данных.
Если чувствуете, что вас привлекает проектирование машинного интеллекта, продолжить образование можно на нашем курсе. Вы научитесь писать алгоритмы, собирать и сортировать данные и получите престижную профессию Data Scientist — специалист по машинному обучению.
Deep Learning: как это работает? Часть 1
В этой статье вы узнаете
-В чем суть глубокого обучения
-Для чего нужны функции активации
-Какие задачи может решать FCNN
-Каковы недостатки FCNN и с помощью чего с ними бороться
Небольшое вступление
Это начало цикла статей о том, какие задачи есть в DL, сети, архитектуры, принципы работы, как решаются те или иные задачи и почему одно лучше другого.
Какие предварительные навыки для понимания всего нужны? Сказать сложно, но если вы умеете гуглить или правильно задавать вопросы, то, я уверен, мой цикл статей поможет разобраться во многом.
В чем вообще суть глубокого обучения?
Суть в том, чтобы построить некий алгоритм, который принимал бы на вход X и предсказывал Y. Если мы пишем алгоритм Евклида для поиска НОД, то мы просто напишем циклы, условия, присваивания и вот это вот все — мы знаем как построить такой алгоритм. А как построить алгоритм, который на вход принимает изображение и говорит собака там или кошка? Или вовсе ничего? А алгоритм, на вход которого мы подаем текст и хотим узнать — какого он жанра? Вот так просто ручками написать циклы и условия тут не выйдет — тут на помощь и приходят нейронные сети, глубокое обучение и все вот эти модные слова.
Более формально и чуть-чуть о функциях активации
Выражаясь формально, мы хотим построить функцию от функции от функции…от входного параметра X и весов нашей сети W, которая выдавала бы нам некий результат. Тут важно отметить, что мы не можем взять просто много линейных функций, т.к. суперпозиция линейных функций — линейная функция. Тогда любая глубокая сеть аналогична сети с двумя слоями (входом и выходом). Для чего нам нелинейность? Наши параметры, которые мы хотим научиться предсказывать, могут нелинейно зависеть от входных данных. Нелинейность достигается путем использования различных функций активаций на каждом слое.
Fully-connected neural networks(FCNN)
Просто полносвязная нейронная сеть. Выглядит как-то так:
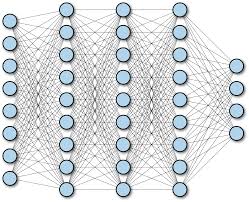
Суть в том, что каждый нейрон одного слоя связан с каждым нейроном следующего и предыдущего (если они есть).
Первый слой — входной. Например, если мы хотим подать изображение 256x256x3 на вход такой сети, то ровно 256x256x3 нейронов во входном слое нам и понадобится (каждый нейрон будет принимать 1 компоненту (R, G или B) пикселя). Если хотим подать рост человека, его вес и еще 23 признака, то понадобится 25 нейронов во входном слое. Кол-во нейронов на выходе — кол-во признаков, которые мы хотим предсказать. Это может быть как 1 признак, так и все 100. В общем случае по выходному слою сети можно почти наверняка сказать — какую задачу она решает.
Каждая связь между нейронами — вес, который тренируется алгоритмом backpropagation, о котором я писал тут.
Какие задачи может решать FCNN
-Задача регрессии. Например, предсказание стоимости магазина по каким-то входным критериям типа страны, города, улицы, проходимости и т.п.
-Задача классификации. Например, классика — MNIST classification.
-Насчет задачи сегментации и обнаружения объектов с помощью FCNN я сказать не возьмусь. Быть может, кто-то поделится в комментариях 🙂
Недостатки FCNN
Глубокое обучение и машинное обучение в Машинном обучении Azure
В этой статье сравнивается глубокое обучение и машинное обучение, а также описывается, как эти технологии соотносятся с более широким понятием искусственного интеллекта. Узнайте о решениях для глубокого обучения, которые можно создавать с помощью Машинного обучения Azure, предназначенных для обнаружения мошенничества, распознавания речи и лиц, анализа тональности и прогнозирования временных рядов.
Рекомендации по выбору алгоритмов для конкретных решений см. на странице Памятка по алгоритмам Машинного обучения.
Глубокое обучение, машинное обучение и искусственный интеллект

Рассмотрим следующие определения для понимания глубокого обучения в сравнении с машинным обучением и искусственным интеллектом.
Глубокое обучение — это разновидность машинного обучения на основе искусственных нейронных сетей. Процесс обучения называется глубоким, так как структура искусственных нейронных сетей состоит из нескольких входных, выходных и скрытых слоев. Каждый слой содержит единицы, преобразующие входные данные в сведения, которые следующий слой может использовать для определенной задачи прогнозирования. Благодаря этой структуре компьютер может обучаться с помощью собственной обработки данных.
Машинное обучение — это подмножество искусственного интеллекта, при котором используются методы (например, глубокое обучение), позволяющие компьютерам использовать опыт для совершенствования в решении задач. Процесс обучения основан на следующих действиях.
Искусственный интеллект (ИИ) — это методика, которая позволяет компьютерам имитировать человеческий интеллект. Сюда же относится и машинное обучение.
С помощью приемов машинного обучения и глубокого обучения можно создавать компьютерные системы и приложения, которые выполняют задачи, обычно поручаемые людям. К этим задачам относятся распознавание изображений, распознавание речи и языковой перевод.
Методы глубокого обучения и машинного обучения
Теперь, когда получены общие сведения о машинном обучении и глубоком обучении, давайте сравним эти два метода. При машинном обучении алгоритму необходимо сообщить, как выполнять точный прогноз, используя дополнительные сведения (например, путем получения данных). В случае глубокого обучения алгоритм сможет обучиться, как создавать точный прогноз путем самостоятельной обработки данных с помощью структуры искусственных нейронных сетей.
В следующей таблице приведено более подробное сравнение этих двух методов.
| Все машинное обучение | Только глубокое обучение | |
|---|---|---|
| Количество точек данных | Для создания прогнозов можно использовать небольшие объемы данных. | Необходимо использовать большие объемы обучающих данных для создания прогнозов. |
| Зависимость от оборудования | Может работать на маломощных компьютерах. Не требуются крупные вычислительные мощности. | Зависит от высокопроизводительных компьютеров. При этом компьютер, по сути, выполняет большое количество операций перемножения матрицы. Графический процессор может эффективно оптимизировать эти операции. |
| Процесс конструирования признаков | Требует точного определения признаков и их создания пользователями. | Распознает признаки высокого уровня на основе данных и самостоятельно создает новые признаки. |
| Подход к обучению | Процесс обучения разбивается на мелкие шаги. Затем результаты выполнения каждого шага объединяются в единый блок выходных данных. | Задача решается методом сквозного анализа. |
| Время выполнения | Обучение занимает сравнительно мало времени — от нескольких секунд до нескольких часов. | Как правило, процесс обучения занимает много времени, поскольку алгоритм глубокого обучения включает много уровней. |
| Выходные данные | Выходными данными обычно является числовое значение, например оценка или классификация. | Выходные данные могут иметь несколько форматов, например текст, оценка или звук. |
Что собой представляет передача обучения?
Обучение моделей глубокого обучения часто требует большого количества обучающих данных, наличия ресурсов для высокопроизводительных вычислений (GPU, TPU) и временных затрат. В случаях, когда доступ к таким ресурсам отсутствует, можно попытаться упростить процесс обучения с помощью методики, известной как перенос обучения.
Перенос обучения — это метод, при котором знания, полученные в результате решения одной задачи, переносятся на другую задачу, связанную с первой.
Структура нейронных сетей такова, что первый набор слоев обычно содержит признаки более низкого уровня, а последний — признаки более высокого уровня, которые нас интересуют. Используя последние слои применительно к новой задаче или области рассмотрения, можно значительно сократить количество времени, данных и вычислительных ресурсов, необходимых для обучения новой модели. Например, у вас имеется модель, которая распознает легковые автомобили, можно переориентировать эту модель путем переноса обучения, чтобы начать распознавать грузовики, мотоциклы и другие виды транспортных средств.
Узнайте, как применить перенос обучения для классификации изображений с помощью платформы с открытым кодом в Машинном обучении Azure. Проведите обучение модели PyTorch глубокого обучения при помощью переноса обучения.
Варианты использования машинного обучения
Благодаря структуре искусственной нейронной сети глубокое обучение прекрасно справляется с поиском закономерностей в неструктурированных данных, таких как изображения, звук, видео и текст. По этой причине глубокое обучение ведет к быстрым преобразованиям в различных отраслях, включая здравоохранение, электроэнергетику, финансы и транспорт. Эти отрасли теперь реорганизуют традиционные бизнес-процессы.
Некоторые из наиболее распространенных применений глубокого обучения проводятся в следующих абзацах. При Машинном обучении Azure можно использовать модель, построенную с помощью платформы на базе открытого исходного кода, или построить модель с помощью предоставляемых средств.
Распознавание именованных сущностей
Распознавание именованных сущностей — это метод глубокого обучения, который воспринимает фрагмент текста в качестве входных данных и преобразует его в предварительно определенный класс. Эта новая информация может быть почтовым индексом, датой или кодом продукта. Затем эти сведения можно хранить в структурированной схеме для создания списка адресов или служить эталоном для подсистемы проверки кода.
Обнаружение объектов
Глубокое обучение зачастую применяется для обнаружения объектов. Обнаружение объектов состоит из двух частей: классификация изображения и его локализация. Классификация изображений распознает изображения объектов (например, автомобилей или людей). Локализация изображений дает конкретное местоположение этих объектов.
Обнаружение объектов уже используется в таких отраслях, как компьютерные игры, розничная торговля, туризм и автомобили с системой автоматического вождения.
Создание заголовка изображения
Как и при распознавании изображений, при создании заголовков изображений система должна создать заголовок, описывающий содержание конкретного изображения. Если у вас имеется технология, позволяющая обнаруживать и помечать объекты на фотографиях, следующим шагом станет преобразование этих меток в описательные предложения.
Как правило, приложения для создания описаний используют сначала сверточные нейронные сети, а затем рекуррентные нейронные сети для преобразования меток в связные предложения.
Машинный перевод
Машинный перевод воспринимает слова или предложения на одном языке и автоматически переводит их на другой язык. Машинный перевод существует уже давно, однако сейчас глубокое обучение позволяет получать впечатляющие результаты в двух конкретных областях: автоматический перевод текста (и перевод речи в текст), а также автоматическое преобразование изображений.
С помощью соответствующего преобразования данных нейронная сеть может понимать текст, звук и визуальные сигналы. Машинный перевод можно использовать для распознавания фрагментов звука в больших звуковых файлах и преобразовывать устную речь или изображения в текст.
Текстовая аналитика
Анализ текста, основанный на методах глубокого обучения, подразумевает анализ больших объемов текстовых данных (например, медицинских документов или денежных чеков), распознавание закономерностей и получение упорядоченной и систематизированной информации.
Компании используют глубокое обучение для анализа текста, чтобы обнаруживать торговлю инсайдерской информацией и обеспечивать соответствие требованиям законодательства. Еще один распространенный пример — мошенничество в области страхования: машинный анализ текста часто используется для анализа больших объемов документов, чтобы распознать случаи возможного мошенничества, выдаваемые за страховой случай.
Искусственные нейронные сети
Искусственные нейронные сети формируются с помощью слоев связанных узлов. В моделях глубокого обучения используются нейронные сети с большим количеством уровней.
В следующих разделах рассматриваются наиболее популярные типы искусственных нейронных сетей.
Нейронная сеть с передачей по очереди
Нейронная сеть с передачей по очереди — это наиболее простой тип искусственной нейронной сети. В сети с передачей по очереди информация перемещается только в одном направлении от входного уровня к выходному. Нейронные сети с передачей по очереди преобразуют входные данные, пропуская их через несколько скрытых слоев. Каждый слой состоит из набора нейронов и полностью соединен со всеми нейронами в предыдущем слое. Последний полностью соединенный слой (выходной слой) представляет собой вывод созданных прогнозов.
Рекуррентная нейронная сеть (RNN)
Рекуррентные нейронные сети — это широко используемые искусственные нейронные сети. Эти сети сохраняют выходные данные слоя и передают его обратно на входной слой, чтобы улучшить прогнозирование на выходе конкретного слоя. У рекуррентных нейронных сетей отличные возможности для обучения. Они широко используются для выполнения сложных задач, таких как прогнозирование временных рядов, обучение распознаванию рукописного ввода и распознавание естественной речи.
Сверточные нейронные сети (CNN)
Сверточная нейронная сеть — это особо эффективная искусственная нейронная сеть, имеющая уникальную архитектуру. Слои в ней организованы в трех измерениях: ширина, высота и глубина. Нейроны в одном слое соединяются не со всеми нейронами в следующем слое, а только с небольшой областью нейронов этого слоя. Окончательный результат сокращается до одного вектора оценки вероятности, упорядоченного по глубине в одном из измерений.
Сверточные нейронные сети используются в таких областях, как распознавание видео, распознавание изображений и в системах выработки рекомендаций.
Генеративно-состязательная сеть (GAN)
Генеративно-состязательные сети — это регенеративные модели, обученные для создания реалистичного содержимого, например изображений. Каждая такая сеть состоит из двух сетей, известных как генератор и дискриминатор. Обе сети обучаются одновременно. Во время обучения генератор использует случайные помехи для создания новых искусственных данных, которые похожи на реальные данные. Дискриминатор принимает выходные данные генератора в качестве входных данных и использует реальные данные, чтобы определить, является ли созданное содержимое реальным или искусственным. Каждая из сетей конкурирует друг с другом. Генератор пытается создать искусственное содержимое, которое не отличается от реального содержимого, в то время как дискриминатор пытается правильно классифицировать входные данные либо как реальные, либо как искусственные. Затем выходные данные используются для обновления веса обеих сетей, чтобы помочь им лучше достичь соответствующих целей.
Генеративно-состязательные сети используются для решения таких проблем, как преобразование изображений в изображения и прогресса возраста.
Преобразователи
Преобразователи — это архитектура модели, которая подходит для решения проблем, содержащих такие последовательности, как текст или данные временных рядов. Они состоят из слоев кодировщика и декодера. Кодировщик принимает входные данные и сопоставляет их с числовым представлением, содержащим определенные сведения, например контекст. Декодер использует информацию из кодировщика для получения выходных данных, например переведенного текста. Преобразователи отличаются от других архитектур, содержащих кодировщики и декодеры, своими вложенными слоями внимания. Внимание: метод концентрации на конкретных частях входных данных на основе важности их контекста относительно других входных данных в последовательности. Например, при суммировании новостных статей не все предложения важны для описания основной идеи. Если сосредоточиться на ключевых словах в статье, формирование сводных данных может быть сделано в одном предложении — в заголовке.
Преобразователи используются для решения проблем обработки естественного языка, таких как перевод, создание текста, ответы на вопросы и формирование сводных данных текста.
Вот некоторые известные примеры реализации преобразователей:
Следующие шаги
В следующих статьях приведены дополнительные варианты использования моделей глубокого обучения с открытым кодом в Машинном обучении Azure.



